

Agentic AI for Data Engineering: Architecture, Use Cases & Real Results [2026 Guide]




Your data engineering team spends between 10% and 30% of their time just finding data issues — and another 10% to 30% fixing them. That's over 770 hours per engineer per year, or more than $40,000 in wasted labor, according to IBM research. And that's before a single insight gets delivered to the business.
Now imagine an AI agent that monitors your pipelines 24/7, detects schema drift the moment it happens, traces root cause across 15 upstream systems in seconds, fixes the issue autonomously if it's within governed rules — and escalates to a human only when it isn't sure.
That's not a vision for 2030. That's agentic AI for data engineering in 2026 — and enterprises that have deployed it are seeing 20% to 40% reductions in operating costs and 12–14 point increases in EBITDA margins.
This guide covers everything: the architecture behind agentic data engineering, the specific use cases where it delivers the highest ROI, real case studies from our enterprise deployments, and a practical framework for implementing it in your organization.
What Is Agentic AI for Data Engineering?
Agentic AI for data engineering refers to autonomous AI agents that can ingest, contextualize, reason over, and act on data pipelines — while operating within governed rules and auditable controls.
This is fundamentally different from adding a ChatGPT wrapper to your data catalog or bolting a copilot onto your SQL editor. Those tools answer questions. Agentic systems take action.
In concrete terms, an agentic data engineering system can independently perform tasks like detecting a schema change in a source system, evaluating which downstream pipelines are affected, deciding whether to auto-remediate or pause and alert, executing the fix, validating the output, and logging every decision for audit — all without a human touching the keyboard.
The shift happening in 2026 is clear: data engineering is moving from human-orchestrated pipelines to agent-orchestrated pipelines where AI agents handle the routine complexity while humans focus on architecture, strategy, and edge cases.
Gartner predicts that by the end of 2026, 40% of enterprise applications will feature task-specific AI agents. For data teams, this means every major component of the modern data stack — ingestion, transformation, quality, observability, and governance — is being augmented or replaced by agentic capabilities.
Why Traditional Data Engineering Is Breaking
Before diving into architecture, it's worth understanding why the current approach is failing at scale. Most enterprise data teams face the same compounding problems:
The volume problem. Enterprise data is growing 20-30% year over year. The number of data sources, schemas, transformations, and consumers is exploding. Manual pipeline management doesn't scale linearly — it scales exponentially in complexity.
The 80% blind spot. Here's a statistic that should alarm every data leader: traditional data stacks only capture approximately 20% of enterprise truth through structured databases and warehouses. The other 80% — trapped in PDFs, emails, Slack conversations, meeting notes, contracts, and support tickets — is invisible to your pipelines. Your data engineering stack is literally blind to 80% of the data that drives business decisions.
The toil problem. Data engineers spend the majority of their time on reactive work: debugging failed jobs, handling schema changes, reconciling data quality issues, and responding to stakeholder complaints about stale or incorrect dashboards. This is skilled labor doing repetitive work that should be automated.
The governance gap. As organizations deploy more data pipelines, governance becomes harder to enforce. Who approved this transformation logic? Why did this value change? When was this pipeline last validated? Most data stacks can't answer these questions, and as compliance requirements tighten — particularly in financial services, healthcare, and regulated industries — this gap becomes a liability.
The freshness problem. Business users want real-time or near-real-time data, but most pipeline architectures were designed for batch processing. Retrofitting real-time capabilities onto batch-first architectures creates fragile, expensive systems that break under load.
Agentic AI doesn't just patch these problems — it fundamentally rearchitects how data work gets done.
The Core Architecture: How Agentic Data Pipelines Work
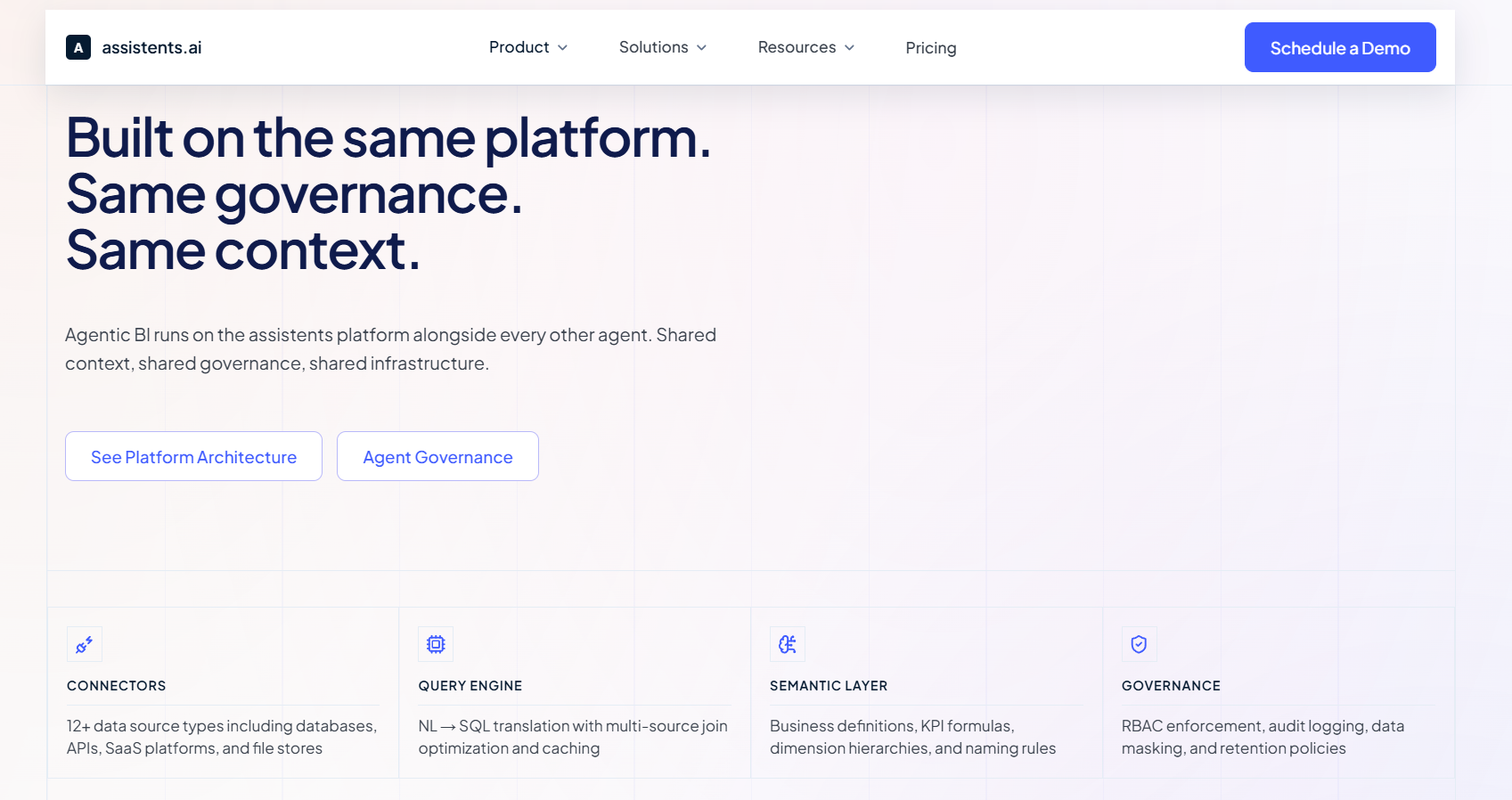
An agentic data engineering system has three core components that work together. Think of them as the agent's brain, its rulebook, and its hands.
1. Unified Context Engine
The context engine is the agent's perception layer. It correlates data from across your entire enterprise — not just structured databases, but unstructured documents, API responses, log files, emails, and external data feeds — into a single semantic representation.
This is what solves the 80% blind spot. Instead of an agent that can only see your Snowflake tables, you get an agent that understands the relationship between a CRM deal record, the contract PDF attached to it, the Slack conversation where the deal was negotiated, and the invoice in your ERP.
How it works technically: the context engine maintains a knowledge graph that maps entities across systems, uses embedding models to create vector representations of unstructured content, and continuously updates as new data arrives. When the agentic system needs to make a decision, it queries this unified context rather than hitting individual source systems.
2. Semantic Governor
The semantic governor is what separates a useful agentic system from a dangerous one. It encodes deterministic business rules and compliance controls that the agent must follow, replacing probabilistic guesses with auditable, governed decisions.
For example, in a financial services context, the governor might enforce rules like: "Auto-process data corrections below $10,000; route anything above to a human approver with full lineage documentation." Or in healthcare: "PHI-containing fields must be masked before any cross-system transfer; log every access for HIPAA audit trail."
The governor provides three critical capabilities. First, approval hierarchies — different actions require different levels of authorization depending on risk and impact. Second, audit trails — every decision the agent makes is logged with full context: what data it saw, what rules applied, what action it took, and why. Third, rule citations — when the agent takes or recommends an action, it can cite the specific business rule or policy that justifies it, providing explainability that regulators and compliance teams require.
3. Agentic Workflow Engine
The execution layer where agents actually do the work. This consists of specialized agents, each with a defined role, that coordinate through a shared orchestration framework.
The most common agent roles in data engineering include:
Ingestion agents that monitor source systems for new data, schema changes, or anomalies, and autonomously adjust connectors and mappings when sources evolve.
Transformation agents that execute and optimize dbt models, SQL transformations, or Python scripts — and can generate new transformations when business requirements change.
Quality agents that continuously validate data against statistical profiles, business rules, and cross-system consistency checks — flagging or auto-remediating issues based on governed thresholds.
Observability agents that monitor pipeline health, predict failures before they happen based on historical patterns, and perform root cause analysis when issues occur.
Governance agents that enforce access controls, track lineage, maintain the data catalog, and ensure every pipeline change is documented and approved.
These agents don't work in isolation. They share context through the unified context engine and follow rules set by the semantic governor. When a quality agent detects an anomaly, it can trigger the observability agent to investigate root cause, which might in turn ask the ingestion agent to check the source system — all autonomously, all governed, all audited.
10 High-Impact Use Cases for Agentic AI in Data Engineering
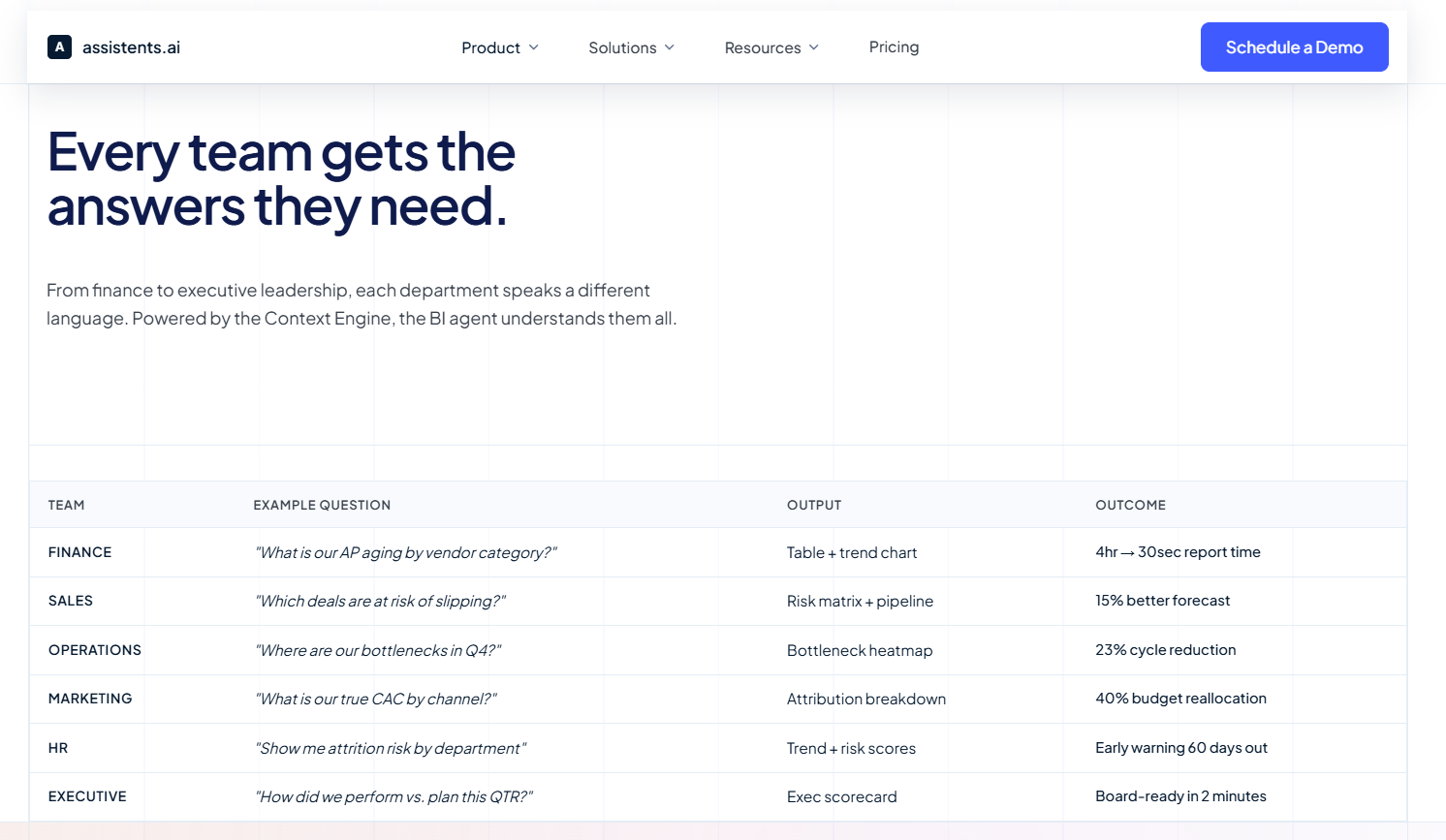
Here are the specific use cases where agentic AI delivers the most measurable value for data engineering teams, ranked by impact and adoption in 2026:
1. Autonomous Root Cause Analysis
The problem: A dashboard shows revenue dropped 15% overnight. A data engineer manually traces the issue across 8 systems over 4 hours, discovers a schema change in a source API that broke a transformation three hops downstream.
The agentic solution: An observability agent detects the anomaly within minutes, traces data lineage across all affected systems, identifies the schema change as root cause, assesses the blast radius (which pipelines, dashboards, and reports are affected), and presents a complete diagnosis with recommended fix — all in under 60 seconds.
Real impact: What took hours of skilled engineering time now takes seconds of agent compute time. More importantly, the agent catches issues that humans might not notice for days or weeks.
2. Self-Healing Data Pipelines
The problem: A source system pushes a breaking schema change at 2 AM. Pipeline fails. Downstream dashboards show stale data for 6 hours until an engineer wakes up, diagnoses the issue, and deploys a fix.
The agentic solution: An ingestion agent detects the schema change in real-time, evaluates whether the change is additive (new column) or breaking (renamed/removed column), and takes appropriate action. For additive changes, it auto-updates the mapping and propagates changes downstream. For breaking changes within governed parameters, it auto-remediates. For high-risk changes, it pauses the pipeline, alerts the on-call engineer with a complete diagnosis and proposed fix, and waits for approval.
Real impact: Pipeline downtime drops from hours to minutes. Engineers get paged with solutions, not problems.
3. Intelligent Data Quality Management
The problem: Data quality rules are static — written once and rarely updated. They catch obvious issues (nulls, type mismatches) but miss subtle problems like distribution drift, cross-table inconsistencies, or business logic violations.
The agentic solution: Quality agents maintain dynamic statistical profiles of every dataset, learning what "normal" looks like and adapting as the business changes. They perform cross-system reconciliation (does the order count in the CRM match the order count in the ERP?), validate business logic constraints (no discount can exceed 40% without VP approval), and detect semantic anomalies that rule-based systems miss.
Real impact: Data quality issues caught before they reach business users. False positive alerts reduced by 60-80% compared to static rule systems because the agent understands context.
4. Governed Multi-Source Data Fusion
The problem: Business decisions require context from structured databases, unstructured documents, and external signals — but these live in completely separate systems with no unified access layer.
The agentic solution: The unified context engine creates a semantic layer that fuses structured data (ERP, CRM, warehouse), semi-structured data (logs, JSON APIs, XML feeds), unstructured data (PDFs, emails, contracts, meeting notes), and external signals (market data, weather, competitor intelligence) into a queryable knowledge graph. Agents can reason across all these data types simultaneously.
Real example: A supply chain agent combining SAP inventory data with weather forecasts, shipping carrier API status, and competitor pricing scraped from public sources — automatically adjusting demand forecasts by +2.8% when it detects a weather event will delay competitor shipments.
5. Automated Data Pipeline Generation
The problem: A product manager requests a new dataset combining data from 4 source systems. A data engineer spends 2 weeks building the pipeline: writing connectors, transformations, quality checks, documentation, and orchestration.
The agentic solution: An agent takes the natural-language requirement ("I need daily updated customer lifetime value combining purchase data from Shopify, support tickets from Zendesk, engagement data from Mixpanel, and demographic data from Salesforce"), generates the pipeline code (ingestion, transformation, quality checks), creates documentation and lineage metadata, deploys to staging for review, and runs validation against sample data — all within hours, not weeks.
Real impact: Pipeline development velocity increases 3-5x. Engineers review and approve agent-generated pipelines rather than writing them from scratch.
6. Real-Time Anomaly Detection and Alerting
The problem: Batch-oriented monitoring catches issues hours or days after they occur. By then, bad data has propagated to dashboards, reports, and downstream systems.
The agentic solution: Observability agents monitor streaming data in real-time, comparing incoming records against statistical baselines and business rules. When they detect an anomaly — a sudden spike in null values, a change in data distribution, or a volume deviation — they immediately assess severity, determine blast radius, and either auto-remediate or alert with full context.
Real impact: Mean time to detection (MTTD) drops from hours to seconds. Mean time to resolution (MTTR) drops from hours to minutes.
7. Automated Compliance and Lineage
The problem: Auditors ask "show me every system that touches customer PII and every transformation applied to it." Data engineers spend days manually tracing lineage across dozens of systems.
The agentic solution: Governance agents maintain real-time, column-level lineage across every pipeline. They automatically classify sensitive fields (PII, PHI, financial data), enforce masking and access controls, log every data access and transformation, and can generate compliance reports on demand — complete with rule citations explaining why each control exists.
Real impact: Compliance audit preparation drops from weeks to hours. Continuous compliance replaces point-in-time audits.
8. Cost Optimization and Resource Management
The problem: Data warehouse costs grow 30-40% year over year as teams add more pipelines without optimizing existing ones. Nobody knows which queries are expensive, which tables are unused, or which transformations could be consolidated.
The agentic solution: Cost optimization agents analyze query patterns, identify expensive but infrequently used materializations, recommend partitioning and clustering strategies, detect duplicate pipelines that could be consolidated, and automatically right-size compute resources based on actual usage patterns.
Real impact: 20-40% reduction in data warehouse and compute costs. Resources freed up for new initiatives rather than paying for technical debt.
9. Cross-Entity KPI Standardization
The problem: A multi-entity enterprise calculates "revenue" differently across 6 business units. Each has its own pipeline, its own definitions, and its own edge cases. The CFO's consolidated report never matches the sum of individual reports.
The agentic solution: Governance agents enforce standardized metric definitions across all entities, automatically detecting when a new pipeline deviates from the canonical definition. They reconcile cross-entity calculations, flag discrepancies with root cause analysis, and maintain an auditable record of every definition change.
Real impact: Consistent, trustworthy metrics across the entire organization. Finance teams spend time analyzing data instead of reconciling it.
10. Semantic Search and Natural Language Data Access
The problem: Business users can't find the data they need. The data catalog has 10,000 tables with cryptic names and incomplete documentation. Users default to asking data engineers, who become bottlenecks.
The agentic solution: A knowledge agent sits on top of the unified context engine, allowing business users to ask natural-language questions like "What was our customer acquisition cost by channel last quarter?" The agent identifies the right tables, writes the query, validates the results against known metrics, and returns the answer — with full lineage so the user knows exactly where the data came from.
Real impact: Self-serve data access increases 3-5x. Data engineering request queues shrink dramatically.
Real Enterprise Case Studies
These aren't hypothetical — they're actual deployments from Assistents by Ampcome's client portfolio across industries and geographies.
Case Study 1: Global Ports & Logistics Leader — Autonomous Port-Inland Logistics Intelligence
Client: A global ports and logistics enterprise with $20B+ in annual revenue and a portfolio spanning ports, terminals, and logistics services worldwide.
Challenge: The client needed to digitize and optimize terminal and rail management operations across multiple facilities. Data was scattered across operational systems, scheduling platforms, and real-time sensor feeds — with no unified intelligence layer connecting them.
What we built: A comprehensive terminal and rail management solution that unified data ingestion from yard operations, rail scheduling, and real-time logistics feeds. The system featured terminal workflow digitization with operational dashboards, rail scheduling and visibility management with automated exception handling, executive dashboards with operational alerts, and agentic agents that could autonomously identify scheduling conflicts and recommend resolutions.
Architecture highlights: Unified context engine correlating structured operational data with semi-structured logistics feeds. Semantic governance layer ensuring all automated decisions followed port authority regulations and safety protocols. Active orchestrator integrated with core terminal management systems.
Impact: Digitized port-inland logistics operations that were previously managed through manual coordination, enabling real-time visibility, proactive exception management, and data-driven optimization across the entire logistics chain.
Case Study 2: Multinational Supply Chain Enterprise — Multi-Entity Analytics Consolidation
Client: A multinational logistics and warehousing company serving customers across India, UK/Europe, and the US, delivering end-to-end supply chain solutions at enterprise scale.
Challenge: As a multi-entity global operation, the client faced the classic KPI standardization problem. Revenue metrics, operational KPIs, and performance indicators were calculated differently across business units and geographies. Leadership couldn't get a consolidated view they trusted.
What we built: An analytics consolidation platform spanning all entities and geographies, featuring cross-entity KPI standardization with consolidated reporting, operational dashboards with variance explanations, and a data quality checks layer with built-in governance. The system provided leadership with a single source of truth that automatically reconciled differences across business units.
Architecture highlights: Agentic data pipeline that ingested data from multiple ERP instances across geographies, standardized definitions through a semantic governance layer, and served consolidated insights through governed dashboards. Every metric was accompanied by lineage documentation showing exactly how it was calculated and from which source systems.
Case Study 3: State Power Utility — Smart Grid Data Engineering at Scale
Client: A state power transmission utility responsible for operating and maintaining transmission systems delivering reliable power across an entire state — serving tens of millions of residents.
Challenge: Managing a state-scale power grid generates massive volumes of sensor and operational data. The utility needed to move from reactive maintenance (fixing things after they break) to predictive operations — but their existing data infrastructure couldn't handle the volume, velocity, or variety of data required.
What we built: A complete data analytics platform for smart grid operations, featuring transmission KPI monitoring with real-time anomaly detection, loss/outage analytics with predictive maintenance indicators, and automated dashboards with alerts for field operations. The system ingested utility and sensor data continuously, applied anomaly detection algorithms, and surfaced actionable alerts to field teams before issues escalated.
Architecture highlights: Real-time data ingestion pipeline processing sensor data from transmission infrastructure across the state. Agentic observability layer that monitored grid performance metrics, detected anomalies against historical baselines, and generated forecasting and optimization recommendations. Automated alert routing ensured the right field teams received the right information at the right time.
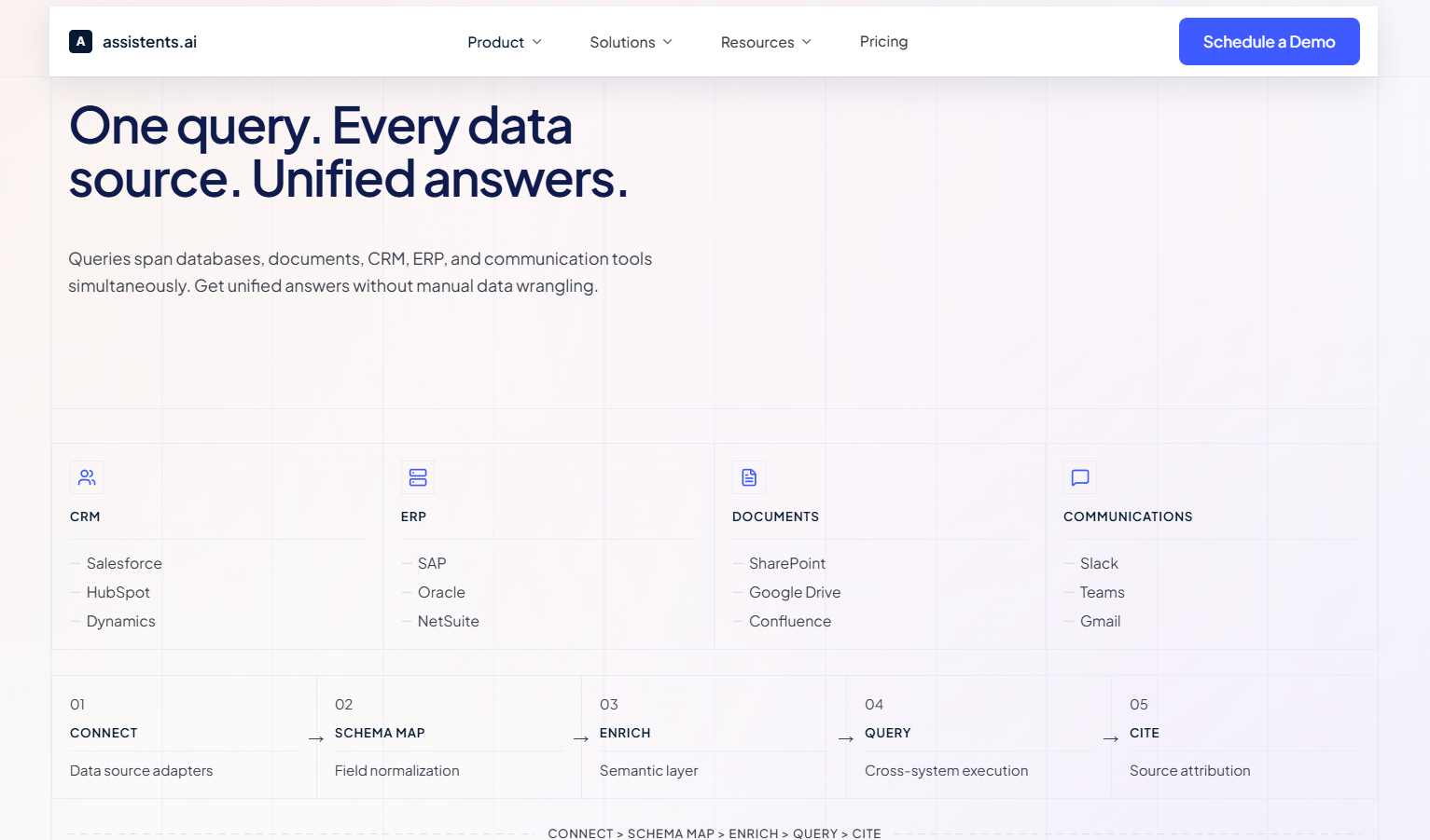
Case Study 4: Multi-Brand Retail Group — From Dashboards to Governed Actions
Client: A privately-held retail holding group where leadership needed governed, cross-functional intelligence across systems and documents to move from insight to action quickly.
Challenge: The group had dashboards — but dashboards don't take action. Leadership would see an insight (inventory levels dropping at specific locations, margin erosion on certain product categories) and then manually coordinate across teams to respond. By the time action was taken, the window of opportunity had often closed.
What we built: An agentic data analysis layer that converts dashboard insights into governed, auditable actions and tasks. The system featured a unified context engine integrating structured and unstructured data, a semantic governance layer encoding business rules and approval hierarchies, an active orchestrator connected to core operational systems, and insights-to-action agents layered on top of existing dashboards.
Architecture highlights: This is the architecture described in our core framework — unified context engine, semantic governor, and agentic workflow engine — deployed in a retail context. The key innovation was the "insights-to-action" pattern: instead of humans reading dashboards and deciding what to do, agents monitored the same metrics and autonomously triggered governed actions when thresholds were crossed.
Case Study 5: Financial Market Analytics Platform — Autonomous Market Data Pipelines
Client: A market research and technical analysis platform using Elliott Wave theory and related indicators to publish forecasts and actionable insights for equity markets.
Challenge: Financial market data engineering is uniquely demanding. Data arrives at high velocity, must be processed with zero tolerance for errors (wrong prices = wrong trading signals), and feeds into time-sensitive analytics that lose value within minutes of delay.
What we built: An autonomous data ingestion and indicator pipeline system, featuring real-time market data ingestion and processing, research automation and insight generation workflows, and alerts with thematic dashboards for analysts and subscribers.
Architecture highlights: High-throughput data ingestion pipeline capable of processing streaming market data. Agentic data science workflows that automatically ran indicator calculations, pattern detection, and signal generation as new data arrived. Automated quality checks ensured data integrity before any analysis was published.
Case Study 6: Global Fintech Provider — Governed Data Pipelines for Banking
Client: A global fintech provider delivering cloud-based automation for banks and credit unions, focused on disputes, fraud, compliance, and operational efficiency.
What we built: Omnichannel AI agents for banking support with auditable workflow automation, including a complete data quality checks and governance layer. The system standardized cross-entity KPI definitions, provided consolidated reporting with variance explanations, and maintained full audit trails for regulatory compliance.
Architecture highlights: Data quality governance was the centerpiece — every data transformation, every metric calculation, and every automated action was logged with full lineage and rule citations. This was critical for a financial services client where regulators require complete traceability of every data-driven decision.
Agentic AI vs. Traditional Data Engineering
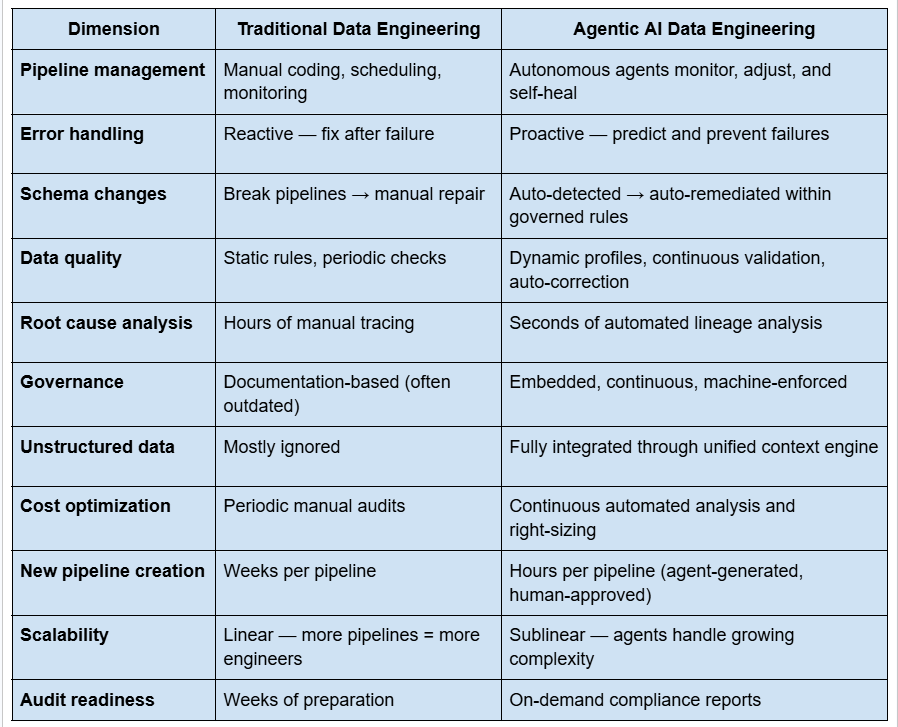
The "Blind Agent" Problem (and How to Solve It)
This is the single most dangerous mistake organizations make with agentic AI in data engineering, and it deserves its own section.
The trap: Organizations build powerful reasoning agents — connected to LLMs with impressive capabilities — and point them at their data warehouse. The agent can reason beautifully over the 20% of enterprise truth that lives in structured databases. But it's completely blind to the other 80% — the emails, contracts, PDFs, Slack conversations, and meeting notes that contain the context necessary for correct decisions.
Why this is catastrophic: A "blind" agent doesn't just give wrong answers. It gives confident wrong answers, at scale, at machine speed. Before a human can intervene, the agent has propagated incorrect transformations across dozens of downstream systems, triggered automated actions based on incomplete context, and created data quality issues that are exponentially harder to unwind than they were to create.
The solution: The unified context engine described in our architecture section is specifically designed to solve this. By fusing structured, semi-structured, and unstructured data into a single semantic representation, you ensure that agents have access to the full picture before making any decision.
In practice, this means your data engineering agents don't just know that revenue dropped 15% — they also know about the pricing change discussed in a Slack channel, the contract renegotiation documented in a PDF, and the strategic shift communicated in an executive email. With full context, the agent makes correct decisions. Without it, it multiplies chaos.
How to Implement Agentic AI in Your Data Stack
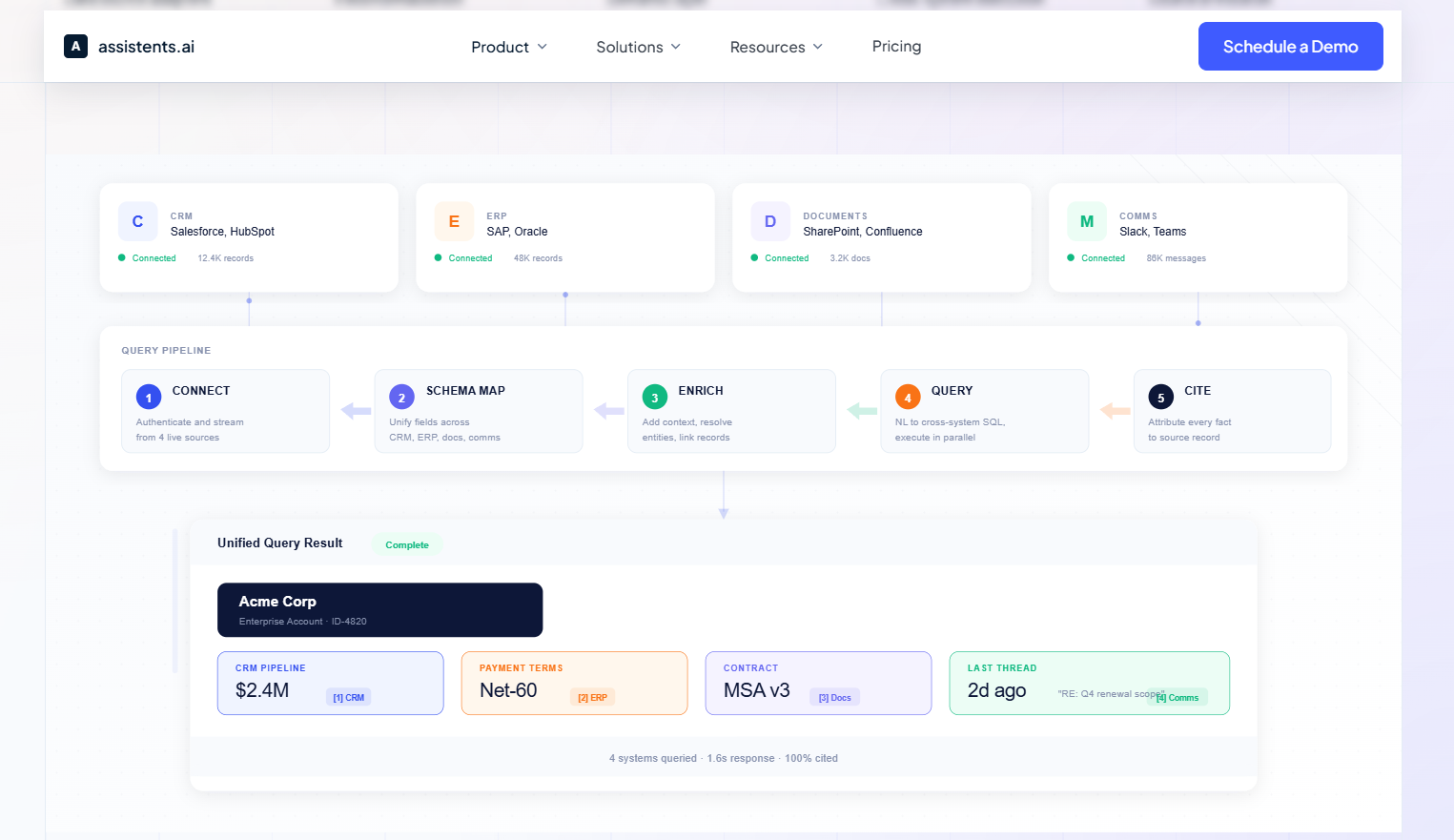
A practical, phased approach for data engineering leaders who want to move from traditional pipelines to agentic systems:
Phase 1: Observe and Augment (Weeks 1–4)
Start with observability agents that monitor your existing pipelines without changing them. Deploy anomaly detection on your most critical data flows. Let the agents watch, learn patterns, and surface insights — but don't give them execution authority yet.
Goal: Build confidence in agent recommendations. Establish baseline metrics (MTTD, MTTR, data quality scores) to measure improvement later.
Quick wins: Automated root cause analysis, intelligent alerting (reduced false positives), and pipeline health dashboards.
Phase 2: Assist and Automate (Weeks 5–12)
Give agents execution authority for low-risk, high-frequency tasks. Auto-remediation of known schema changes. Auto-healing of common pipeline failures. Automated data quality corrections within defined thresholds.
Goal: Free up 30-40% of engineering time currently spent on reactive work.
Key requirement: Implement the semantic governor before granting execution authority. Every autonomous action must be governed, auditable, and reversible.
Phase 3: Orchestrate and Scale (Months 3–6)
Deploy multi-agent workflows where specialized agents collaborate on complex tasks. Automated pipeline generation. Cross-system data fusion. Proactive governance enforcement.
Goal: Transform data engineering from a bottleneck into an accelerator. Business stakeholders get data faster, more reliably, and with better governance.
Phase 4: Autonomous Operations (Month 6+)
The data engineering system operates primarily through agent orchestration. Humans focus on architecture decisions, edge cases, and strategic direction. Agents handle the rest.
Goal: 10x improvement in pipeline velocity with better quality, governance, and reliability than manual operations achieved.
Tools and Frameworks for Agentic Data Engineering in 2026
The tooling landscape is evolving rapidly. Here's what's relevant for data engineering teams building agentic systems:
Orchestration frameworks: LangChain and LangGraph for agent workflow design. CrewAI for multi-agent coordination. AutoGen for complex, multi-step task decomposition. These provide the scaffolding for building agent systems that can plan, execute, and iterate.
Data infrastructure: Databricks (with Genie Code for agentic data access), Snowflake Cortex for in-warehouse AI, Apache Kafka for real-time data streaming, and dbt for transformation logic that agents can generate and execute.
Vector databases: Pinecone, Weaviate, Chroma, and pgvector for the embedding-based storage that powers the unified context engine — enabling semantic search across structured and unstructured data.
Observability: Monte Carlo, Soda, and Great Expectations for data quality monitoring that agents can integrate with. Datadog and Grafana for infrastructure observability.
Governance: Informatica's enterprise AI agent engineering platform, Atlan for metadata management, and custom semantic governor implementations for business-rule enforcement.
Foundation models: OpenAI GPT-4o, Anthropic Claude, Google Gemini, and Meta Llama — the reasoning engines that power agent decision-making. Choice depends on cost, latency, accuracy, and enterprise requirements (on-prem vs. cloud).
Ready to Transform Your Data Engineering with Agentic AI?
At Ampcome, we've deployed agentic data engineering systems for enterprises across logistics, financial services, utilities, retail, and manufacturing — from $20B+ global operations to state-scale infrastructure serving tens of millions. Our architecture framework (unified context engine + semantic governor + agentic workflow engine) has been battle-tested across 30+ enterprise deployments.
Whether you're looking to automate pipeline observability, implement governed data quality, or build a full agentic data engineering platform, we can take you from strategy to production.
Book a Free 15-Minute Discovery Call →
Explore Our AI Agent Development Services →
Frequently Asked Questions
What is agentic AI for data engineering? Agentic AI for data engineering refers to autonomous AI agents that can independently manage data pipelines — ingesting, transforming, validating, and governing data without constant human oversight. Unlike traditional automation that follows static scripts, agentic systems can reason about problems, plan multi-step solutions, and adapt to changing conditions while operating within governed rules.
How is agentic AI different from traditional BI and data tools? Traditional BI tools answer "what happened" using structured data in dashboards. Agentic AI data engineering systems go further — they answer "why it happened" by tracing lineage across systems, "what will happen next" through predictive analysis, and "what should we do about it" by taking autonomous governed actions. They also integrate unstructured data (documents, emails, conversations) that traditional BI ignores entirely.
What is the "blind agent" problem? The blind agent problem occurs when organizations deploy AI agents that can only access structured databases — roughly 20% of enterprise data. These agents make decisions based on incomplete context, which can lead to confident but incorrect actions executed at machine speed. The solution is a unified context engine that integrates structured, semi-structured, and unstructured data sources before any agent decision.
How does governance work in agentic data systems? Governance is enforced through a semantic governor — a rules engine that encodes deterministic business logic and compliance requirements. Every agent action is validated against these rules before execution. The governor enforces approval hierarchies (different actions require different authorization levels), maintains complete audit trails, and provides rule citations explaining why each decision was made. This is critical for regulated industries like financial services and healthcare.
Can agentic AI integrate with existing data stacks? Yes. Agentic systems are designed as a layer on top of existing infrastructure — SAP, Salesforce, Snowflake, Databricks, Kafka, dbt, and other tools you already use. The unified context engine connects to your existing systems through APIs, database connectors, and file system integrations. You don't rip and replace — you augment and extend.
How much does it cost to implement agentic AI for data engineering? Costs depend on scope and complexity. A focused deployment targeting pipeline observability and root cause analysis might cost $50,000-$150,000. A comprehensive implementation with multi-agent orchestration, unified context engine, and semantic governance for a large enterprise typically ranges from $200,000-$750,000+. However, organizations typically see ROI within 6-12 months through reduced engineering toil, faster incident resolution, and improved data quality. Contact us for a detailed estimate →
What's the difference between agentic AI and RPA for data workflows? RPA (Robotic Process Automation) follows pre-scripted steps — it can move data from point A to point B but can't adapt when conditions change. Agentic AI reasons about problems, makes decisions under uncertainty, handles edge cases, and improves over time. Think of RPA as a very fast typist and agentic AI as a junior data engineer who can think, plan, and learn. For a deeper comparison, see our guide on agentic process automation vs RPA.

Transform Your Business With Agentic Automation
Agentic automation is the rising star posied to overtake RPA and bring about a new wave of intelligent automation. Explore the core concepts of agentic automation, how it works, real-life examples and strategies for a successful implementation in this ebook.
Sarfraz Nawaz is the CEO and founder of Ampcome, which is at the forefront of Artificial Intelligence (AI) Development. Nawaz's passion for technology is matched by his commitment to creating solutions that drive real-world results. Under his leadership, Ampcome's team of talented engineers and developers craft innovative IT solutions that empower businesses to thrive in the ever-evolving technological landscape.Ampcome's success is a testament to Nawaz's dedication to excellence and his unwavering belief in the transformative power of technology.
More insights
Discover the latest trends, best practices, and expert opinions that can reshape your perspective







Contact us

