

AI Agents for Data Quality Checks: How Enterprises Eliminate Data Failures at Scale in 2026




Poor data quality costs the average enterprise $12.9 million every year, according to Gartner. That number is not driven by catastrophic system failures. It is driven by the slow, invisible accumulation of stale records, inconsistent fields, duplicate entries, and uncaught pipeline anomalies that compound across every system your business runs on.
The traditional response to this problem has been to add more rules, more validation scripts, and more analysts running weekly reconciliation reports. It does not scale. As data estates grow — spanning ERP systems, CRMs, data warehouses, SaaS platforms, and real-time operational feeds — the gap between what rule-based tools can catch and what actually breaks widens every quarter.
AI agents for data quality checks are a fundamentally different approach. Rather than executing a fixed checklist on a schedule, they monitor continuously, learn from patterns, adapt to changing data conditions, and trigger remediation without waiting for a human to notice something is wrong. For VP-level data and analytics leaders managing complex enterprise environments, they represent the difference between a reactive cleanup cycle and a continuously trusted data estate.
This guide explains what these agents actually do, how they work across real enterprise environments, and what a phased implementation looks like — including examples from production deployments across logistics, financial services, retail, and energy.
What Are AI Agents for Data Quality Checks?
AI agents for data quality checks are autonomous software systems that connect to enterprise data sources, continuously profile incoming data, detect anomalies and integrity violations, and trigger corrective workflows — without requiring manual intervention at each step.
The distinction from traditional tools is not just about speed. It is about architecture. Rule-based data quality tools execute predefined checks on a defined schedule. If a new data pattern emerges that the rules do not cover, it goes undetected. If a pipeline schema changes, validation breaks until someone updates it manually. The tools are as good as the rules written into them, and maintaining those rules at enterprise scale becomes a full-time job.
AI agents operate differently across four core dimensions:
They monitor continuously rather than on a schedule, which means issues are detected when they occur rather than during the next batch run — often hours or days later.
They adapt to evolving data patterns using machine learning, so when normal seasonal variation changes the expected range for a field, the agent adjusts its thresholds rather than flooding your team with false positives.
They prioritize by business impact, identifying which datasets drive the most downstream decisions and intensifying monitoring there first.
And they act — either auto-correcting well-understood issues like missing zip codes or duplicate contacts, or routing complex exceptions to the right human with full context already assembled.
How AI Agents Differ from Rule-Based Data Quality Tools
Rule-based tools require you to know what questions to ask before you ask them. You define the constraint — "this field cannot be null," "this value must fall between 0 and 100," "this record must have a matching entry in the reference table" — and the tool checks for violations. When something unexpected happens that you did not anticipate, the rule does not catch it.
AI agents invert this. They observe the data, model what "normal" looks like across every field, detect deviations from that baseline, and surface anomalies that no one wrote a rule for. They are particularly effective at catching distribution shifts — subtle, gradual changes in data composition that indicate upstream problems long before they become visible as hard failures.
Key Capabilities — What AI Data Quality Agents Actually Do
A production-ready AI agent for data quality operates across four interconnected functions: continuous monitoring of pipeline health and field completeness across all connected sources; anomaly detection using learned baselines rather than static thresholds; automated remediation of routine violations with full audit logging; and governance enforcement that ensures every action is traceable, documented, and aligned with data policies.
The Six Dimensions of Data Quality AI Agents Enforce Continuously
Data quality is conventionally described across six dimensions. What the best-practice guides rarely explain is how an AI agent handles each one differently than a traditional tool — and why that difference matters at enterprise scale.
Accuracy is the degree to which data correctly represents the real-world entity it describes. Rule-based tools check accuracy by comparing values against reference tables. AI agents go further: they cross-validate records across multiple connected systems simultaneously, flagging inconsistencies that only become visible when sources are compared in real time. A customer record that looks accurate in the CRM but conflicts with the billing system is invisible to a single-system rule check and obvious to a multi-source agent.
Completeness measures whether all required data is present. Traditional tools flag null fields. Agents do this too, but they also detect patterns of incompleteness — for example, a subset of records systematically missing a field that correlates with a specific data entry workflow, indicating a process problem upstream rather than random gaps.
Consistency means data is uniform across systems and time periods. In multi-entity enterprises — a holding group with thirty operating companies, or a retailer with hundreds of store locations — consistency is the dimension most likely to fail silently. An agent deployed across a group-wide context can detect when the same KPI is being calculated differently across two business units before that discrepancy reaches a leadership report.
Timeliness tracks whether data is current and available when needed. Agents monitor pipeline freshness continuously, alerting the moment a feed goes stale rather than waiting for a downstream team to notice that yesterday's data is still showing in today's dashboard.
Validity means data conforms to defined formats, types, and business rules. Agents enforce validity at ingestion — catching a malformed date field or an out-of-range value the moment it enters the pipeline, before it propagates to dependent tables.
Uniqueness ensures no entity is duplicated across the data estate. Deduplication has historically required expensive, periodic master data management projects. AI agents apply deduplication logic continuously, using probabilistic matching to identify near-duplicate records that an exact-match rule would miss.
How AI Agents Run Data Quality Checks — Step by Step
Understanding the operational flow of an AI data quality agent helps data leaders evaluate what they are actually deploying and set realistic expectations for what it replaces.
Step 1 — Connection and profiling. The agent connects to data sources through standard APIs — data warehouses, ERP systems, CRMs, SaaS platforms, streaming feeds. On initial connection, it profiles every table and field: distributions, nullability rates, update frequency, record volumes, and relationship patterns across tables. This profiling establishes the baseline against which all future monitoring is measured.
Step 2 — Continuous monitoring. Once baselines are established, the agent monitors all connected sources on a near-real-time basis. It is not running a checklist. It is watching for deviations from expected behavior across every dimension: a field that normally has 2% nulls suddenly showing 18% nulls, a daily record volume that drops by 40% without a corresponding business event, a value that falls outside the historical range for that field.
Step 3 — Anomaly detection and classification. When a deviation is detected, the agent classifies it by type, severity, and likely root cause. It uses lineage data to identify where in the pipeline the issue originated and which downstream datasets are affected. High-impact anomalies in certified, frequently-used datasets are escalated immediately. Anomalies in low-traffic or deprecated tables are logged and reviewed on a lower-priority basis.
Step 4 — Automated remediation for known issue types. Routine violations — formatting errors, missing values with predictable fills, duplicate records identified by high-confidence matching — are corrected automatically with the action logged to an audit trail. The agent does not proceed silently; every auto-correction is documented with the rule that triggered it, the original value, and the corrected value.
Step 5 — Human-in-the-loop escalation. Complex exceptions — anomalies that require business judgment, schema changes that need architectural review, issues affecting certified production datasets — are escalated to the appropriate data steward with full context already assembled: what changed, where it originated, what is affected, and what resolution options are available. The analyst receives a brief, not a raw alert.
Step 6 — Governance logging. Every action — detection, classification, auto-correction, escalation, and resolution — is written to an immutable audit log. This supports compliance reporting, root cause analysis, and continuous improvement of the agent's behavior over time.
Continuous Monitoring vs Batch Processing
The operational difference is significant. Batch processing finds problems after the fact — often after they have already propagated downstream and reached a dashboard, a decision, or a regulatory report. Continuous monitoring catches issues at the point of entry, before they travel. In environments where data freshness is a competitive or compliance-critical factor, this distinction is the difference between a proactive data operation and a reactive one.
How AI Agents Learn from Corrections Over Time
Every correction a human data steward approves — confirming an agent's flag, overriding an auto-correction, reclassifying an anomaly — feeds back into the agent's model. Patterns that initially required human review become auto-corrections executed with high confidence. The system improves without requiring manual rule updates. This is the adaptive quality layer that rule-based tools cannot replicate: the agent gets better at your data, not just at generic data patterns.
Human-in-the-Loop Controls for Complex Exceptions
Enterprise-grade AI data quality agents are not autonomous systems operating without oversight. They are governed systems that escalate decisions appropriately. For data that touches financial reporting, compliance obligations, or patient records, the agent's role is to detect, classify, and brief — not to correct unilaterally. Human-in-the-loop controls are configurable at the dataset level, ensuring that the governance posture matches the sensitivity of the data.
Enterprise Use Cases — Where AI Data Quality Agents Deliver the Most Value
The following use cases are drawn from production deployments across enterprise clients. Client names are not disclosed; each is described by industry, scale, and the specific data quality problem the agent was deployed to solve.
Supply Chain and Logistics — Multi-Entity Data Consolidation
A multinational logistics and supply chain operator running operations across multiple countries faced a persistent challenge: KPI definitions and calculation methods varied across business units, making consolidated reporting unreliable. Finance reported one set of fulfillment numbers; operations reported another. Leadership could not reconcile them without manual intervention from analysts who were already stretched.
An AI data quality agent was deployed with a cross-entity semantic governance layer — a unified set of metric definitions, hierarchies, and business rules that all connected entities were required to conform to. The agent monitored pipeline outputs from each business unit, detected calculation inconsistencies in real time, and flagged them for resolution before they reached consolidated dashboards. Reporting cycles that previously required multi-day analyst intervention were reduced significantly, and leadership gained confidence in numbers that had previously required a disclaimer.
Financial Services — Transaction Data Integrity and Compliance Audit Trails
A fintech provider delivering cloud-based automation for banks and credit unions required continuous data integrity monitoring across disputes, fraud workflows, and compliance reporting. The consequence of data quality failures in this environment is not an incorrect dashboard — it is a regulatory exposure.
An omnichannel AI agent was deployed across the intake, workflow routing, and case management layers, continuously validating transaction records, monitoring for completeness across mandatory fields in compliance reports, and maintaining immutable audit logs for every data state change. The audit log capability alone reduced the time to assemble compliance evidence packages, replacing a process that had required manual data extraction across multiple systems.
Retail — Inventory, Pricing, and Promotional Data at Scale
A national value retailer operating hundreds of stores across a large geography ran into the challenge that characterises large-scale retail data: the sheer volume of SKUs, promotions, pricing tiers, and inventory records creates a data surface too large for manual quality checks to cover meaningfully.
An AI agent was deployed to monitor pricing data, inventory records, and promotional configurations continuously across the store network. It detected discrepancies between central pricing records and point-of-sale system data, flagged promotional configurations that conflicted with margin rules, and surfaced inventory anomalies indicating data entry errors at store level. Store-level data accuracy improved, and the analytics team shifted from running manual reconciliation reports to reviewing agent-generated exception summaries.
Energy and Utilities — Smart Grid Monitoring and Anomaly Detection
A state power transmission utility responsible for grid operations across a large territory needed continuous data quality monitoring across transmission KPIs, sensor feeds, and operational alerts. In a grid environment, data quality is not an analytics problem — it is an operational safety problem. A stale or incorrect reading from a sensor can delay a response to a developing fault.
An AI agent was deployed across smart grid data feeds, monitoring for sensor data freshness, field completeness in operational dashboards, and anomalies in transmission KPI trends. The agent generated automated alerts for field operations teams when data integrity indicators fell below defined thresholds, and produced predictive maintenance indicators based on historical performance patterns in the sensor data.
Healthcare — Patient Record Completeness and Governed Compliance Workflows
Healthcare data quality operates under a distinct constraint that no other industry shares: errors do not just affect decisions — they affect patient outcomes and carry direct regulatory consequences under frameworks like HIPAA.
A physician-led clinical services provider operating across multiple care settings deployed an AI data quality agent to monitor patient record completeness, validate clinical data against mandatory field requirements, and maintain audit trails aligned with compliance obligations. The agent flagged incomplete records at the point of entry — before they reached clinical or billing workflows — and routed them for completion with the specific missing fields identified, rather than returning them as generic errors.
AI Agents vs Traditional Data Quality Tools — A Practical Comparison
The table below compares the three common approaches to enterprise data quality across the dimensions that matter most to data and analytics leaders making build-or-buy decisions.
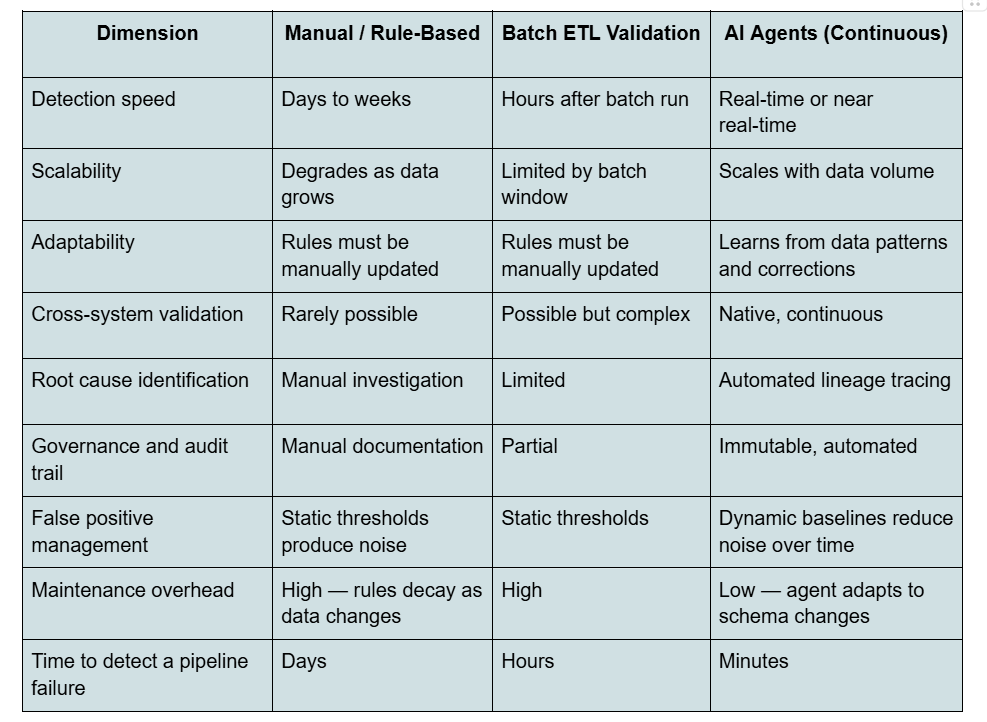
The pattern that emerges is consistent: rule-based and batch approaches require increasing human maintenance as the data estate grows. AI agents have the opposite dynamic — their maintenance burden decreases over time as the system learns, and their coverage expands without proportional increases in analyst time.
AI Agents for VP Data and Analytics — Connecting Quality to Intelligence
Data quality is not an end in itself. Clean data is only valuable when it flows reliably into the business intelligence, reporting, and decision-making workflows that depend on it. This is where the connection between data quality agents and the broader analytics layer becomes critical.
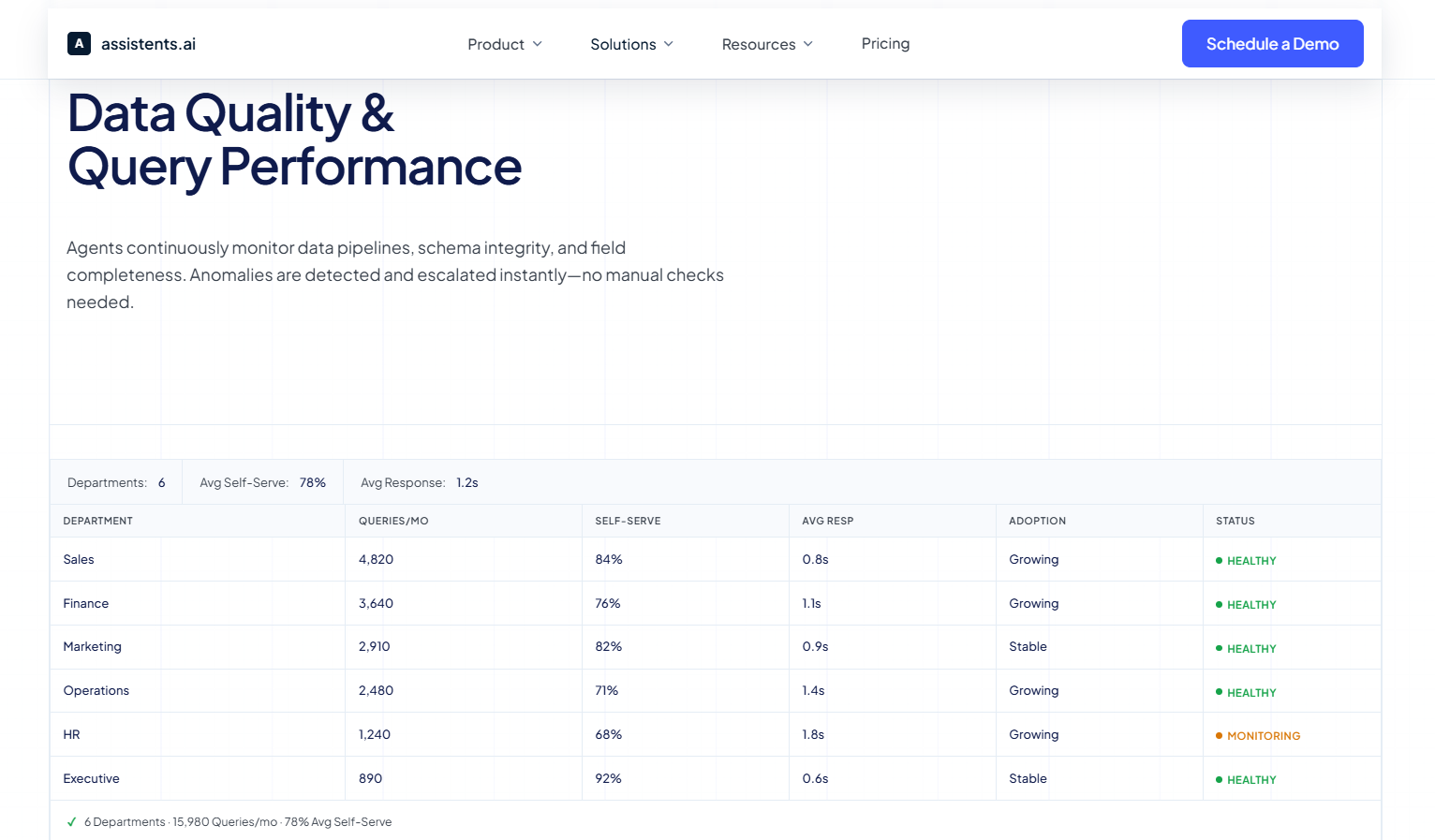
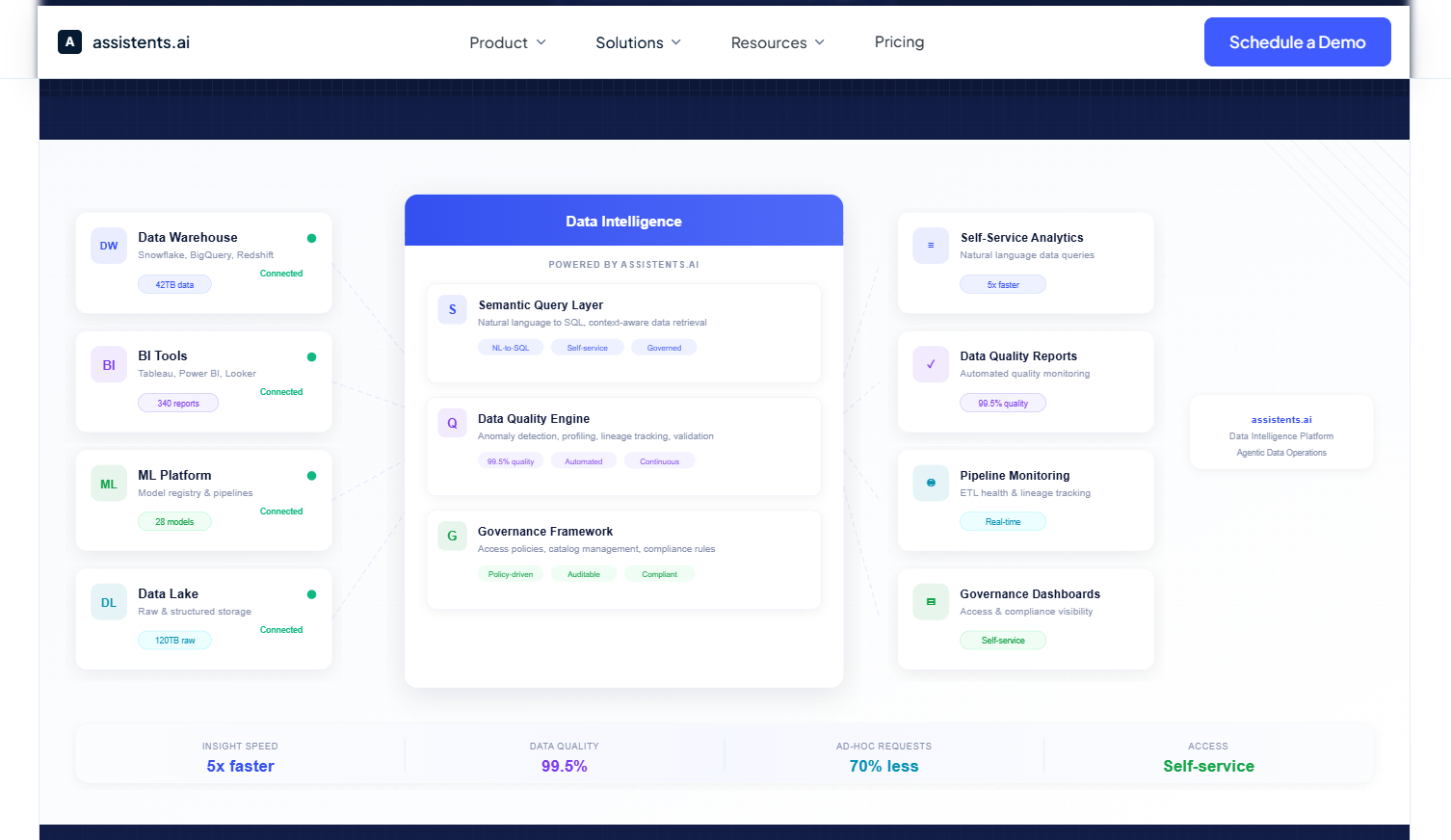
The enterprise analytics platform built for VP Data and Analytics leaders at assistents.ai integrates continuous data quality monitoring directly into the analytics pipeline. Agents monitor data sources — Snowflake, Salesforce, PostgreSQL, HubSpot, Stripe, and more — tracking freshness, quality scores, row volumes, and pipeline latency in real time. When a source falls below the quality threshold required for reliable analysis, the agent flags it before it reaches a dashboard or a business query.
This means that when a business user asks a plain-language question — "What is our fulfillment rate by region this week?" — the agent answering that question is not just querying data. It is querying data it has already validated, from sources it has already confirmed are current and complete. The self-serve analytics layer and the data quality layer are not separate systems bolted together. They are the same governed pipeline.
Production deployments of this architecture have achieved a 95% data quality score across connected sources, with 80% of analytical queries handled without involving the data team directly — because the data underpinning those queries is continuously trusted, not periodically audited.
For data leaders managing organizations where analyst capacity is constrained and business demand for data access is growing, this architecture solves both problems simultaneously: it improves data reliability while reducing the analyst time required to maintain it.
Explore how the VP Data and Analytics solution at assistents.ai delivers continuous data quality automation, self-serve BI, and governed pipeline monitoring in a single enterprise-grade platform.
How to Implement AI Agents for Data Quality — A Practical Framework
The most common reason enterprise data quality AI initiatives stall is not technical. It is scope. Teams attempt to connect every system, enforce every quality dimension, and achieve full automation in a single deployment. The result is a project that takes twelve months to show any value, loses stakeholder confidence, and gets deprioritized.
A phased approach — connecting one high-impact system, proving value in weeks, and expanding from there — consistently outperforms comprehensive deployments in both speed to value and organizational adoption.
Phase 1: Connect one high-impact source (Weeks 1–2)
Start with the data source that causes the most downstream pain when it fails. This is usually the data warehouse feeding your primary executive dashboard, your CRM, or your core ERP. Connect the agent, let it profile the source for three to five days to establish baselines, then activate monitoring. Within the first week, you will typically see the agent surface anomalies that your team either did not know about or had been discovering manually days after they occurred.
Phase 2: Configure quality dimensions and thresholds (Weeks 2–3)
Work with the agent's initial anomaly detections to calibrate. Some flagged anomalies will be genuine issues. Some will be expected business patterns — end-of-quarter spikes, promotional record volumes — that need to be incorporated into the baseline. This calibration phase is where the agent begins to model your data specifically, not generic data patterns. Set auto-correction rules for the violation types where confidence is high and impact of an incorrect correction is low.
Phase 3: Enable continuous monitoring across priority sources (Weeks 3–6)
Expand connection to the next tier of data sources, prioritized by the frequency with which they feed critical business decisions. Enable freshness monitoring and completeness checks across all connected sources. Begin delivering weekly quality score reports to data stakeholders — this creates visibility into the value being generated and builds organizational confidence in the agent.
Phase 4: Activate governed remediation workflows (Weeks 6–8)
Configure the escalation paths for exceptions that require human judgment. Define which datasets require human-in-the-loop approval before auto-corrections are applied. Connect the agent's alert and escalation outputs to your existing ticketing or workflow system — ServiceNow, Jira, or equivalent — so that data quality exceptions enter the same resolution queue as other operational issues.
Phase 5: Add the semantic governance and audit layer (Weeks 8–12)
Deploy the semantic governance layer: unified metric definitions, cross-entity consistency rules, and the immutable audit trail that records every data state change. This is the layer that transforms your data quality operation from a monitoring function into a compliance-ready, audit-ready governance infrastructure.
Integration Requirements
Production AI data quality agents connect through standard APIs and pre-built connectors. In well-designed platforms, integration with a Snowflake data warehouse, a Salesforce CRM, a PostgreSQL operational database, or a SaaS marketing platform requires configuration, not custom development. For on-premise ERP environments — SAP, Oracle — connector availability and data residency requirements should be validated before architecture decisions are finalized.
Governance and Audit Trail Configuration
Every action taken by the agent — detection, classification, auto-correction, escalation, and resolution — should write to an immutable, timestamped audit log. For enterprises operating under SOC 2, GDPR, HIPAA, or ISO 27001 obligations, this audit capability is not optional. It is the mechanism by which the AI system's actions become defensible in an audit or regulatory review. Configure audit logs to capture the original data value, the corrected value, the rule or model that triggered the action, the timestamp, and the identity of any human who approved or overrode the agent's decision.
Measuring Success — KPIs for Data Quality Improvement
Before deployment, establish baseline measurements across four metrics: data quality score (percentage of records passing all active quality checks), pipeline freshness rate (percentage of sources delivering data within their expected latency window), time-to-detection for quality failures (how long from failure occurrence to alert), and analyst hours spent on manual data validation per week. Review these metrics monthly. A well-deployed AI data quality agent should show measurable improvement across all four within the first 90 days.
What a Trusted Data Estate Actually Enables
The ROI case for AI agents in data quality is not primarily about the cost of fixing bad data. It is about the cost of every business decision made on data that was not trustworthy — the forecast built on stale numbers, the procurement decision made on inconsistent supplier records, the executive dashboard that showed last week's inventory.
Enterprises that have deployed continuous AI data quality agents consistently report the same pattern: the immediate benefit is fewer fire drills. The compounding benefit is that every system built on top of the data estate — every dashboard, every AI model, every self-serve analytics query — becomes more reliable simultaneously. Clean data at the source is a multiplier on every downstream investment in data and analytics infrastructure.
For data and analytics leaders building the case for investment, that multiplier effect is the argument. You are not buying a data quality tool. You are buying the confidence layer that makes every other data investment perform as intended.
So, automate data quality monitoring, eliminate pipeline failures before they reach your dashboards, and give your business teams the data confidence to make faster decisions — all within a governed, audit-ready enterprise platform.
Explore the VP Data and Analytics solution at assistents.ai →
Frequently Asked Questions
What types of data quality issues can AI agents detect automatically?
AI agents for data quality checks detect a broad range of issue types automatically, including: null or missing values in required fields, duplicate records identified through probabilistic matching, values outside historical distribution ranges, schema changes that break downstream dependencies, pipeline freshness failures where data stops arriving within its expected window, and cross-system consistency violations where the same entity is represented differently across connected data sources.
How do AI agents for data quality differ from traditional ETL validation?
Traditional ETL validation executes predefined rules during data transformation — it checks for violations you anticipated when you wrote the validation logic. AI agents continuously monitor live data against learned baselines, detect anomalies that no predefined rule covers, adapt to changing data patterns without manual rule updates, and trace issues back to their origin using data lineage. ETL validation is a checkpoint; AI agents are continuous surveillance.
Can AI agents enforce data quality across multiple enterprise systems simultaneously?
Yes. This cross-system capability is one of the primary advantages of AI agents over single-system validation tools. An enterprise data quality agent connects to all data sources in the estate — warehouses, CRMs, ERPs, SaaS platforms, streaming feeds — and monitors them simultaneously. Critically, it can detect consistency violations that only become visible when multiple sources are compared: the same customer record appearing with different values in the CRM and the billing system, or the same KPI calculated differently by two business units.
What governance controls are available for AI-driven data quality management?
Production-grade AI data quality platforms provide: row-level security ensuring agents only access data they are authorized to see, immutable audit logs recording every detection and action, human-in-the-loop approval requirements configurable at the dataset level, semantic versioning of governance rules and thresholds, and integration with existing identity and access management systems via SAML-based SSO. All of these controls are configurable to match the governance posture appropriate for each data domain.
How long does it take to deploy an AI agent for data quality checks?
Initial deployment — connecting to the first data source, establishing monitoring baselines, and activating anomaly detection — can be completed in two to three weeks for standard data warehouse and SaaS platform integrations. Full deployment across a multi-system enterprise estate, including governed remediation workflows and semantic governance configuration, typically takes eight to twelve weeks. Production deployments consistently achieve measurable quality improvements within the first 30 days of monitoring a single source.
Are AI data quality agents compliant with GDPR, HIPAA, SOC 2, and ISO 27001?
Enterprise-grade AI data quality platforms are designed for compliance from the ground up. This includes data residency controls (including on-premise and private cloud deployment options for environments where data cannot leave the organizational boundary), HIPAA-compliant handling of protected health information, SOC 2 Type II certified infrastructure, GDPR-aligned data processing agreements, and the immutable audit trails required to demonstrate compliance in regulatory reviews. Compliance certifications should be validated at the platform level, not assumed from product descriptions.

Transform Your Business With Agentic Automation
Agentic automation is the rising star posied to overtake RPA and bring about a new wave of intelligent automation. Explore the core concepts of agentic automation, how it works, real-life examples and strategies for a successful implementation in this ebook.
Sarfraz Nawaz is the CEO and founder of Ampcome, which is at the forefront of Artificial Intelligence (AI) Development. Nawaz's passion for technology is matched by his commitment to creating solutions that drive real-world results. Under his leadership, Ampcome's team of talented engineers and developers craft innovative IT solutions that empower businesses to thrive in the ever-evolving technological landscape.Ampcome's success is a testament to Nawaz's dedication to excellence and his unwavering belief in the transformative power of technology.
More insights
Discover the latest trends, best practices, and expert opinions that can reshape your perspective







Contact us

