

What Is Pinecone Serverless? How It Cuts Vector DB Costs by 50x (Updated April 2026)




If you are building enterprise AI agents, a RAG pipeline, or any LLM application that needs to retrieve context at scale, the infrastructure layer matters as much as the model. And nothing in that infrastructure layer has changed the cost calculus more dramatically than Pinecone Serverless — a vector database architecture that separates reads, writes, and storage to deliver up to 50x cost reduction over traditional pod-based indexes.
This guide covers what Pinecone Serverless is, exactly how it reduces costs, how it compares to the pod-based model, and — critically — where it fits inside an enterprise AI agent stack like the one powering platforms built on the Assistents.ai architecture.
Why This Matters in 2026
Pinecone Serverless is not just cheaper. It changes the economic model of vector search entirely — from a fixed monthly infrastructure cost to a usage-based model that scales to zero when idle. That difference matters enormously for enterprise deployments running dozens of AI agents across multiple departments.
What Is a Vector Database — And Why Enterprises Need One
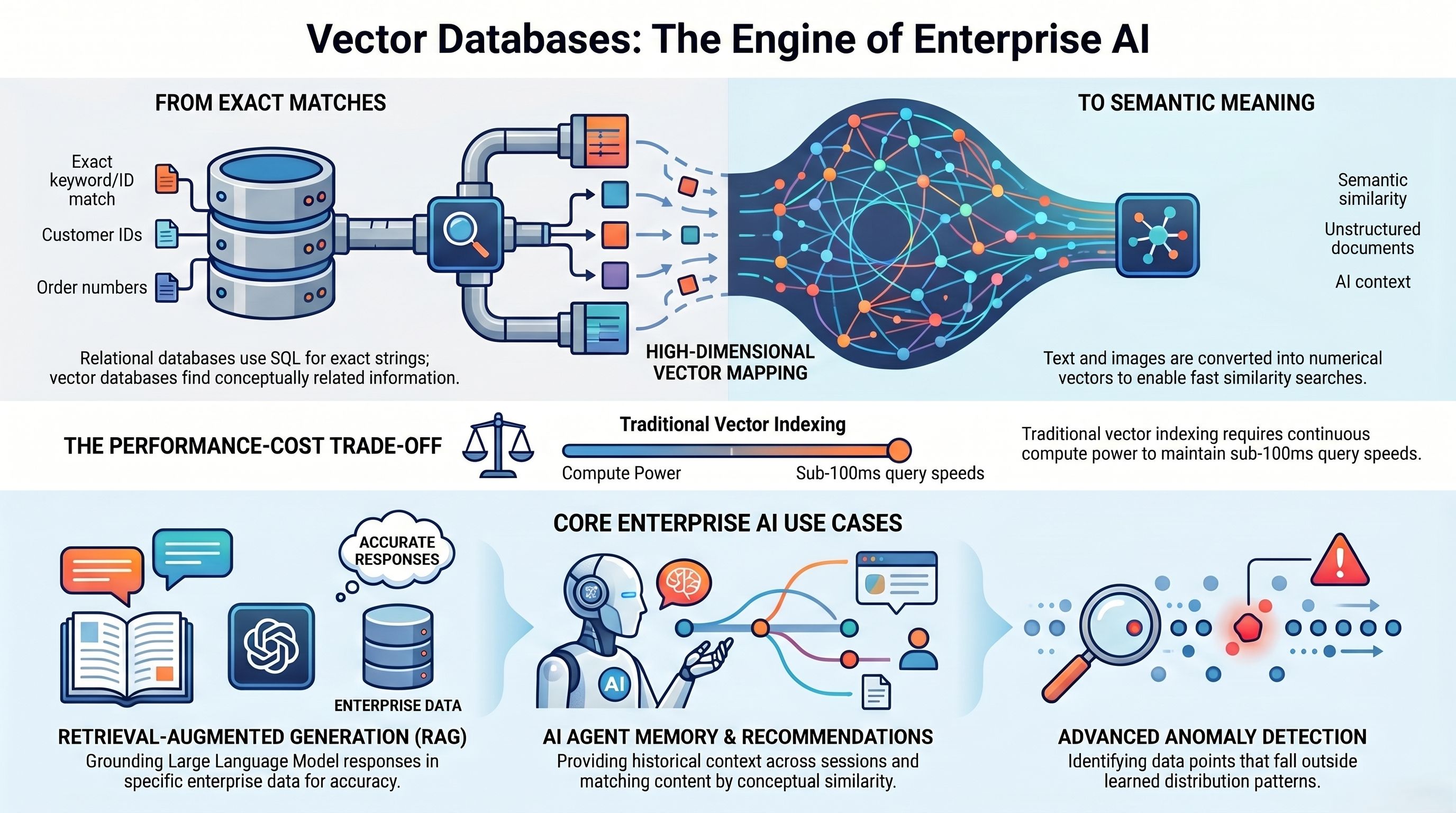
Before getting into Pinecone Serverless specifically, it is worth grounding the conversation in why vector databases exist.
Standard relational databases store and retrieve data based on exact matches — a customer ID, an order number, a specific string. But AI applications do not work with exact matches. They work with semantic meaning. When an AI agent is asked 'What were the key risks flagged in last quarter’s compliance reports?', there is no SQL query that can answer that. The agent needs to search across unstructured documents, find the semantically closest matches to the question, and retrieve them as context.
Vector databases solve this by converting text, images, and documents into high-dimensional numerical vectors and enabling fast similarity search across billions of these vectors. That is what powers:
- Retrieval-Augmented Generation (RAG) — grounding LLM responses in enterprise data
- Semantic search — finding relevant documents without keyword matching
- AI agent memory — giving agents access to historical context across sessions
- Recommendation engines — matching products, people, or content by conceptual similarity
- Anomaly detection — flagging vectors that fall outside learned distribution patterns
The problem has always been cost. Maintaining a vector index that can serve sub-100ms queries across millions of records requires significant compute — and traditionally, that compute ran continuously whether or not queries were being made. That is the problem Pinecone Serverless was built to solve.
What Is Pinecone Serverless?
Pinecone Serverless is a next-generation vector database architecture that decouples storage from compute — meaning you are not paying for a running server. Instead, the system stores vector indexes in blob storage and loads only the relevant portions into memory at query time.
This is architecturally different from the pod-based model that Pinecone and most vector databases used before. In the pod model, you provision infrastructure upfront: choose a pod type, choose a size, pay a flat rate. Your vectors live in memory on that pod. Whether you run one query or ten million that month, the cost is roughly the same.
Serverless flips that entirely:
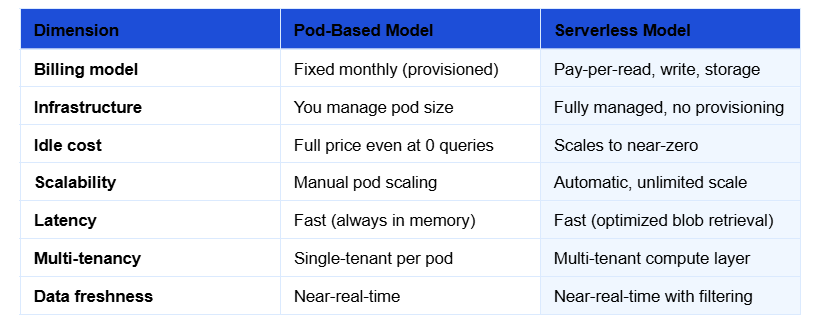
The serverless architecture is available across AWS, GCP, and Azure regions. Usage-based billing covers three dimensions: reads (query units), writes (write units), and storage (GB). You are only paying for what your AI agents actually do.
How Pinecone Serverless Reduces Costs by Up to 50x
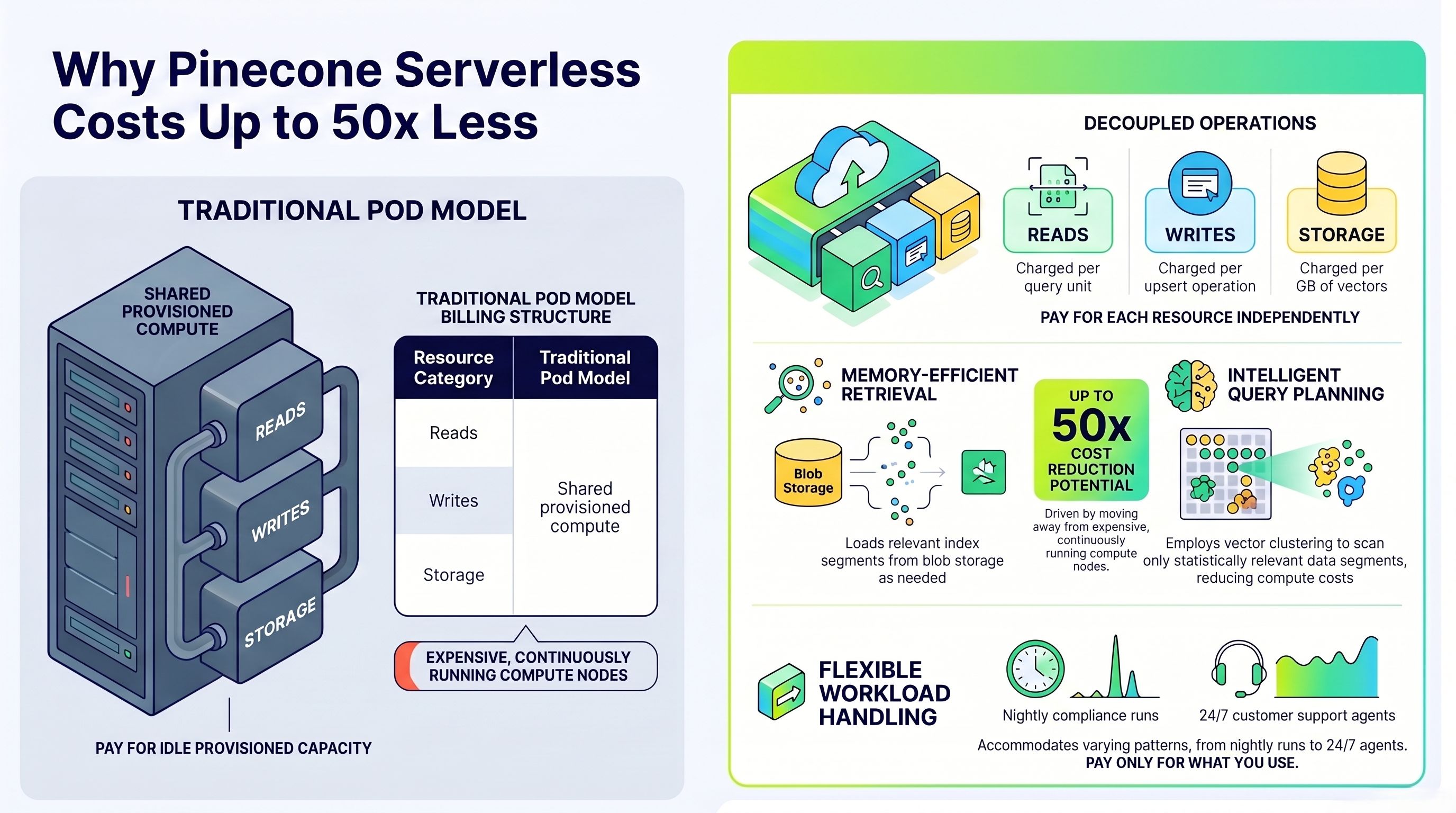
The cost reduction is not a marketing language. It is the result of three specific architectural innovations that together change how vector search is priced.
- Memory-Efficient Retrieval
Traditional vector search loads the entire index into memory and performs a brute-force similarity scan. That requires large, expensive compute nodes running continuously. Pinecone Serverless uses a scatter-gather mechanism that loads only the relevant index segments needed to answer a specific query — directly from blob storage. The result: memory requirements drop dramatically, and so does cost.
- Intelligent Query Planning
The retrieval algorithm does not scan the full index for every query. It uses vector clustering over blob storage to identify which data segments are statistically likely to contain the nearest neighbors for a given query vector, then scans only those segments. This reduces both latency and compute cost per query.
- Separation of Reads, Writes, and Storage
This is the core structural difference. In a pod model, all three operations share the same provisioned compute — you pay for the whole machine even when only one operation type is running. Serverless prices each independently:
- Read units: charged per query. If agents are idle, you pay nothing.
- Write units: charged per upsert operation. Batching writes reduces cost.
- Storage: charged per GB of vectors stored. No compute markup.
🔵 Enterprise Implication
For enterprise AI agent deployments where different agents run at different times across different departments, the serverless model is almost always dramatically cheaper. A compliance agent that runs nightly, an invoice agent that runs in bursts during month-end, and a customer support agent running 24/7 can each be priced appropriately for their actual usage pattern — rather than all sharing a single provisioned pod.
Key Features of Pinecone Serverless (2026 Update)
Beyond the cost architecture, Pinecone Serverless ships with a set of features relevant to enterprise AI agent deployments:
Namespace Isolation
Vectors can be organized into namespaces within a single index, enabling different AI agents to maintain isolated context spaces without requiring separate indexes. A finance agent, HR agent, and supply chain agent can each operate in their own namespace within the same serverless index — reducing overhead while maintaining governance boundaries.
Metadata Filtering
Every vector can carry metadata fields (document type, date, department, classification level), and queries can be filtered by these fields. This is essential for governed enterprise AI agents that need to retrieve only information a specific user role is authorized to access.
.jpg)
Hybrid Search Support
Pinecone Serverless supports combining dense vector search with sparse keyword search — a technique known as hybrid search. For enterprise use cases where exact terms matter alongside semantic meaning (e.g., searching for a specific policy document number while also matching intent), hybrid search significantly improves recall accuracy.
SDK and Integration Support
Full SDK support for Python, Node.js, Java, and Go. Native integrations with LangChain, LlamaIndex, OpenAI, Anthropic, Cohere, and all major embedding providers. API-compatible with any enterprise stack, including SAP, Salesforce, ServiceNow, and Oracle environments where AI agents are increasingly being deployed.
No Infrastructure Management
There are no servers to provision, patch, or scale. The entire operational burden of running a vector database — replication, failover, capacity planning — is abstracted away. For enterprise AI teams whose engineering bandwidth is focused on agent logic rather than infrastructure, this matters enormously.
When to Use Pinecone Serverless vs. Pod-Based Indexes
Serverless is not always the right choice. Here is a practical decision framework:
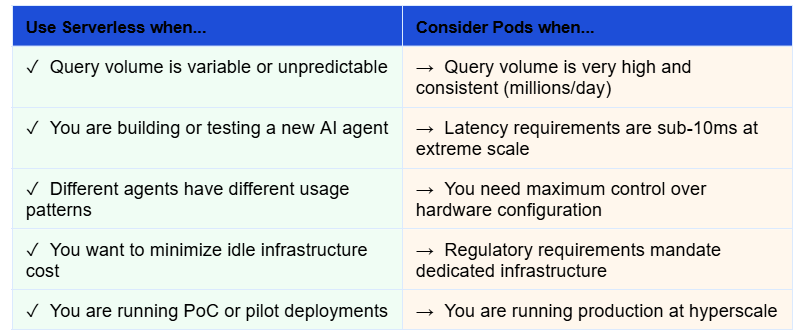
The majority of enterprise AI agent deployments — particularly in their first 12 to 24 months — will see meaningful cost savings with the serverless model. The break-even point where pod-based pricing becomes cheaper typically occurs only at sustained query volumes exceeding several hundred million queries per month.
Pinecone Serverless Inside an Enterprise AI Agent Stack
Understanding Pinecone Serverless in isolation is useful. Understanding where it sits inside a full enterprise AI agent architecture is where it becomes strategically relevant.
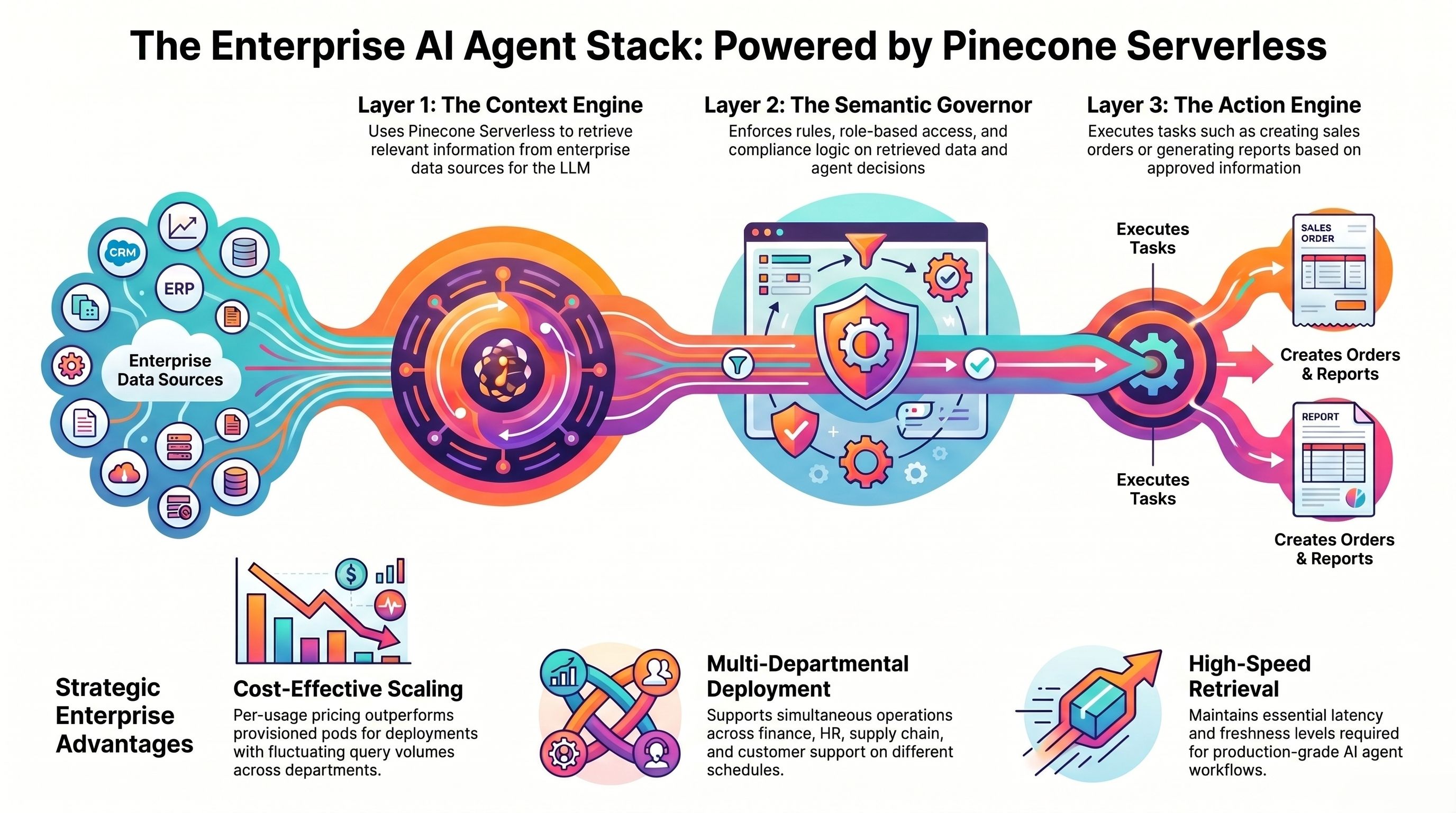
A production-grade enterprise AI agent platform — the kind that can execute multi-step workflows across SAP, Salesforce, ServiceNow, and internal databases simultaneously — has three core layers:
- Context Engine: retrieves relevant information from enterprise data sources before the LLM acts. This is where vector search lives. Pinecone Serverless is the retrieval layer.
- Semantic Governor: enforces rules, role-based access, and compliance logic on what the agent can retrieve, decide, and act on.
- Action Engine: executes tasks — creating SAP sales orders, updating Salesforce records, generating compliance reports — based on what the context engine retrieved and the governor approved.
Pinecone Serverless powers the first layer. It is what allows an AI agent to understand the question 'Which of our top 20 suppliers has the highest on-time delivery risk this quarter?' — retrieving relevant contract terms, delivery history, and quality reports from unstructured documents before generating a governed, auditable answer.
Platforms like Assistents.ai implement this three-tier architecture with enterprise-grade governance — making Pinecone Serverless a natural infrastructure choice for the retrieval layer, particularly for deployments that span multiple departments with different query volume patterns.
🔵 Architecture Note
If your enterprise AI agent deployment spans finance, HR, supply chain, and customer support simultaneously — each running on different schedules and query volumes — Pinecone Serverless's per-usage pricing model will almost certainly outperform a single provisioned pod on cost, while maintaining the latency and freshness your agents need.
Getting Started with Pinecone Serverless
The setup is straightforward. Pinecone Serverless is available directly from the Pinecone console and is the default option for new index creation.
- Create an account at pinecone.io — new accounts receive $100 in free usage credits.
- Create a serverless index — choose your cloud provider (AWS, GCP, Azure) and region. No pod type selection required.
- Choose your embedding model — Pinecone supports any embedding provider (OpenAI, Cohere, Google Vertex, Anthropic, and open-source models). Match the embedding dimension to your model output (e.g., 1536 for OpenAI text-embedding-3-small).
- Upsert your vectors — batch your upserts for cost efficiency. Pinecone recommends batches of 100 vectors per upsert call.
- Query with metadata filters — use namespace and metadata filtering to route queries to the right agent context and enforce access controls from the start.
Cost optimization tip: Organize your vectors into namespaces aligned with your agent architecture from day one. A namespace per department, per data source type, or per agent role makes both cost attribution and access governance significantly easier to manage as your deployment scales.
The Bottom Line
Pinecone Serverless is one of the most practically significant infrastructure decisions in an enterprise AI agent deployment. The architectural shift from provisioned pods to usage-based compute is not incremental — it changes the fundamental cost model of running vector search at scale.
For organizations deploying AI agents across multiple departments, with different usage patterns and query volumes, the serverless model delivers three compounding benefits: lower infrastructure cost, zero operational overhead, and pricing that scales with actual value delivered rather than theoretical peak capacity.
If your organization is building or scaling enterprise AI agents and wants to understand how the retrieval layer fits into a governed, multi-department deployment, the Assistents.ai platform is built around exactly this architecture — with a Context Engine designed for enterprise-grade RAG, a Semantic Governor for compliant data access, and an Action Engine that turns retrieved context into auditable business outcomes.
→ See how Assistents.ai handles enterprise AI agent deployment at scale
Frequently Asked Questions
Is Pinecone Serverless suitable for production enterprise deployments?
A: Yes. Pinecone Serverless is production-ready and used by enterprises running high-volume AI agent workloads. It is particularly well-suited for deployments with variable query patterns across multiple use cases. For extremely high and consistent query volumes — over several hundred million per month — pod-based indexes may offer better per-query economics, but the majority of enterprise deployments will find serverless more cost-effective.
How does Pinecone Serverless handle data security and compliance?
A: Pinecone Serverless supports encryption at rest and in transit, role-based access controls, and VPC peering for private network connectivity. It is SOC 2 Type II certified. For enterprise deployments with strict data residency requirements, you can select the specific cloud region where your data is stored.
What is the latency difference between Pinecone Serverless and pod-based indexes?
A: For typical enterprise RAG workloads — queries returning the top 10 to 100 nearest neighbors from indexes of up to several hundred million vectors — the latency difference is minimal and within acceptable bounds for synchronous AI agent responses. Pod-based indexes may have a slight edge at extreme scale, but for most enterprise use cases, serverless latency is operationally equivalent.
Can I migrate from a pod-based index to Pinecone Serverless?
A: Yes. Pinecone provides migration tooling and documentation for moving from pod-based to serverless indexes. The process involves creating a new serverless index and re-upserting your vectors. Pinecone’s support team can assist with large-scale migrations.
How does Pinecone Serverless integrate with enterprise AI agent platforms?
A: Pinecone Serverless integrates via REST API and official SDKs for Python, Node.js, Java, and Go. It is pre-integrated with major AI orchestration frameworks including LangChain and LlamaIndex, as well as enterprise AI agent platforms that implement RAG-based context retrieval. Most enterprise platforms that use a context-first architecture can integrate Pinecone Serverless as the retrieval layer within a standard implementation sprint.
Sarfraz Nawaz is the CEO and founder of Ampcome, which is at the forefront of Artificial Intelligence (AI) Development. Nawaz's passion for technology is matched by his commitment to creating solutions that drive real-world results. Under his leadership, Ampcome's team of talented engineers and developers craft innovative IT solutions that empower businesses to thrive in the ever-evolving technological landscape.Ampcome's success is a testament to Nawaz's dedication to excellence and his unwavering belief in the transformative power of technology.
Other Articles
Explore the frontiers of innovation in Artificial Intelligence, breaking barriers and forging new paths that redefine possibilities and transform the way we perceive and engage with the world.




%20%26%20Why%20Its%20A%20Hot%20Topic%20For%20Enterprise%20AI.webp)
Ready To Supercharge Your Business With Intelligent Solutions?
At Ampcome, we engineer smart solutions that redefine industries, shaping a future where innovations and possibilities have no bounds.
.avif)
