

How to Use Groq API: The Comprehensive Guide You Need




Updated March 2026 — This guide now includes new Groq models (Llama 4 Scout, GPT-OSS, Kimi K2, Qwen3), updated free tier rate limits, current pricing, and production considerations for enterprise teams. Originally published March 2024.
In today's competitive landscape, a one-second delay in loading a webpage can drop the number of visitors by 11%. Groq API emerges as a solution through its Language Processing Unit (LPU) technology, which can process 100 output tokens at a recorded speed of 0.8 seconds, positioning it as among the fastest interfaces available for AI applications.
What is Groq?
Groq represents a California-based AI company focused on designing advanced AI solutions. The company offers innovative products including Groq API, Groq LPU, and Groq Chip, significantly impacting the artificial intelligence landscape through solutions emphasizing exactness, speed, and seamless handling of large datasets without latency.
What is Groq LPU?
Groq LPU (Language Processing Unit) is groundbreaking technology that enhances traditional AI computing abilities, mainly in the LLM domain.
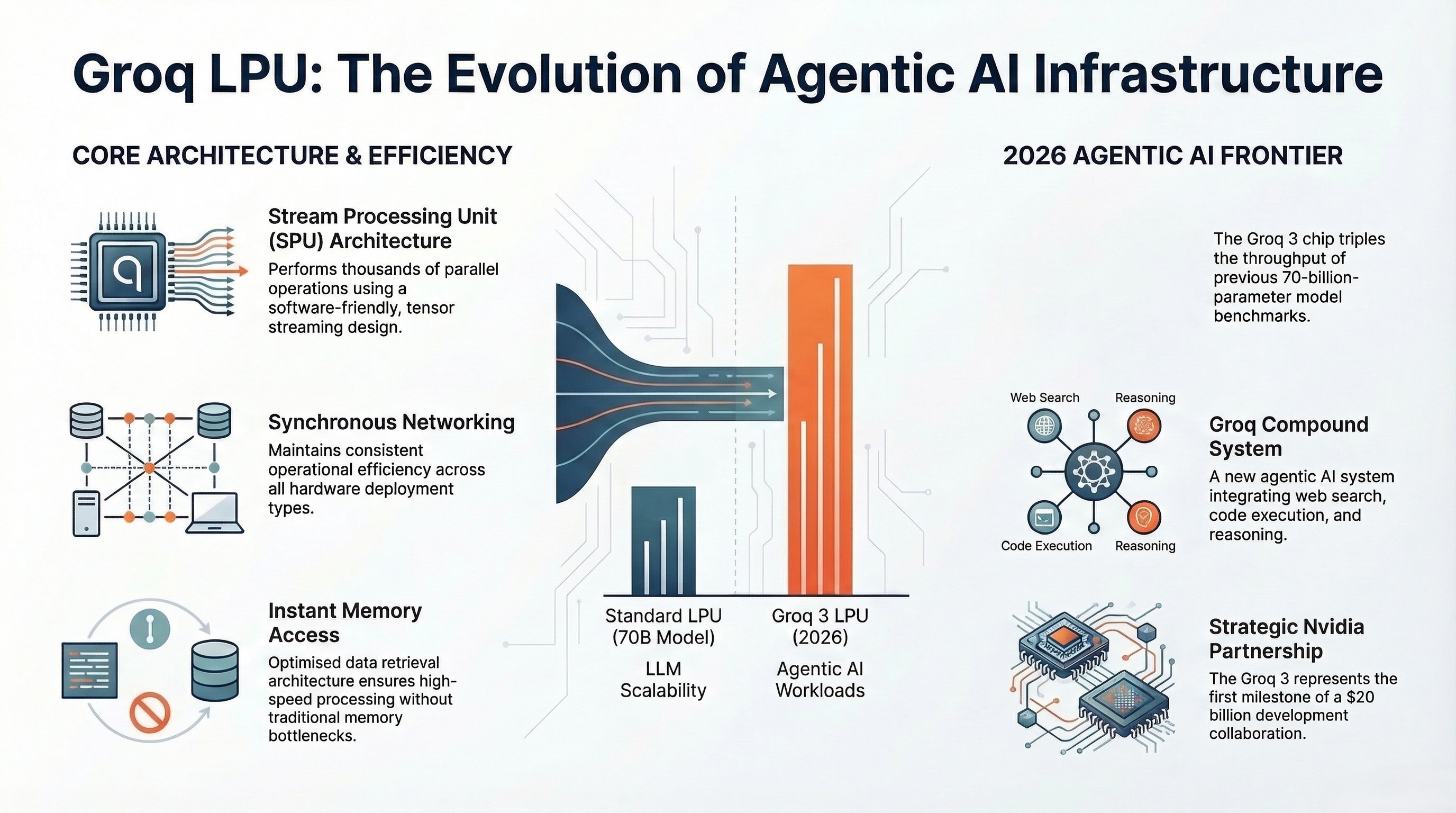
Key Characteristics:
- Stream Processing Unit (SPU) Architecture — Performs thousands of operations such as task allocation and data processing in parallel with software-friendly design optimization.
- Synchronous Networking — Maintains synchronous networking across all deployment types, enhancing operational efficiency.
- Scalability — Features auto-compile capability enabling compilation of 70-billion-parameter language models at 500 tokens per second.
- Memory Access — Provides instant memory access promoting optimized data retrieval and processing.
- Groq Chip Component — Based on tensor streaming architecture, optimized for accuracy and speed, operates on cloud with high computing capabilities.
2026 Update: In March 2026, Groq announced the Groq 3 LPU chip — the first chip developed under Nvidia's $20 billion partnership. The Groq 3 targets 1,500 tokens per second throughput specifically designed for agentic AI workloads, a significant leap from earlier generations. Groq has also launched Groq Compound, an agentic AI system now in general availability that combines web search, code execution, and multi-step reasoning on top of the LPU infrastructure.
What is Groq API?
Groq API functions as a cornerstone technology enabling developers to integrate cutting-edge Large Language Models (LLMs) into their solutions. The API streamlines development through compatibility with multiple platforms and scalability support.
Benefits Include:
- Ultra-low latency in AI interfaces
- High computing capabilities
- Diversified development supporting TensorFlow execution, containerization, and Python SDK
- Swift elimination of coordination issues in traditional multi-core architectures
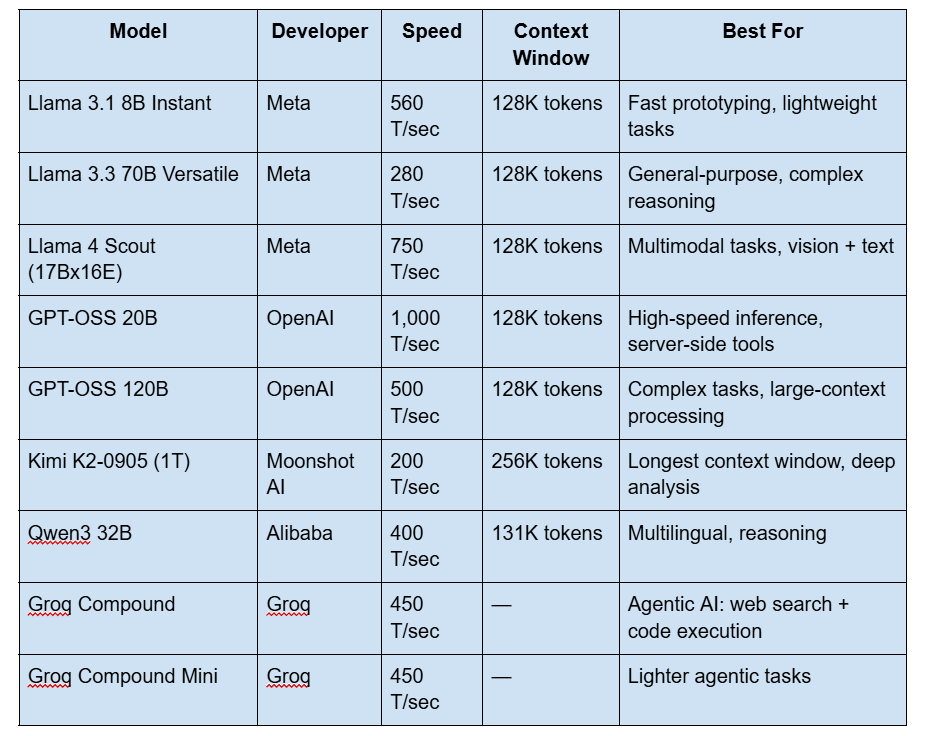
Groq API Available Models (2026)
Since this guide was first published, Groq has dramatically expanded its model catalog. Here are all currently available models as of March 2026:
Production Models
Audio Models
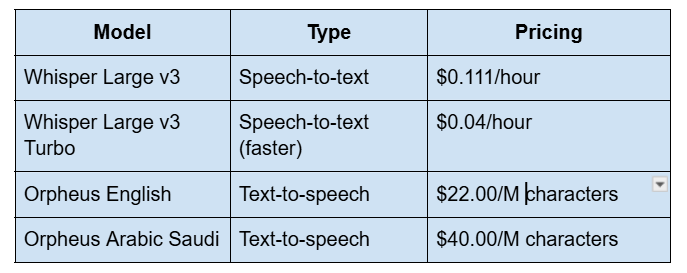
Note: Gemma 2 has been deprecated — Groq recommends Llama 3.1 8B Instant as the replacement. Llama 2 (referenced in the original version of this guide) has also been fully retired.
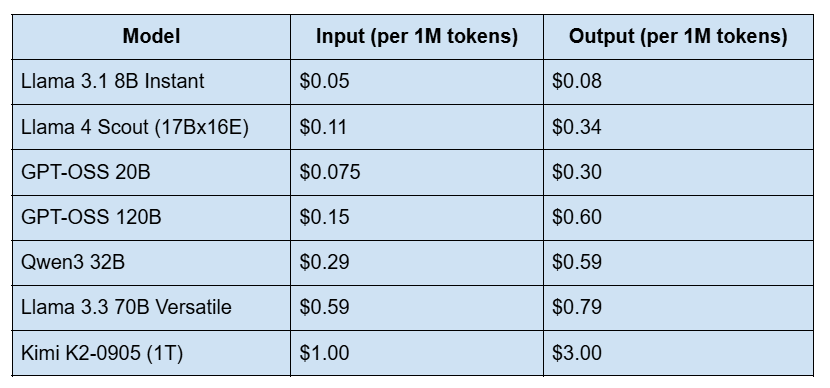
Groq API Pricing (2026)
Groq charges per million tokens on a pay-as-you-go basis. No minimum spend, no commitment required.
Cost-saving options:
- Prompt Caching: 50% off input tokens for repeated prompts (e.g., system prompts that stay the same across requests).
- Batch API: 50% off real-time rates for async jobs with 24-hour to 7-day processing windows.
Groq Free Tier Rate Limits (2026)
This is the most-searched question about Groq right now — and the answer changes by model. Here are the exact free tier limits as of March 2026:
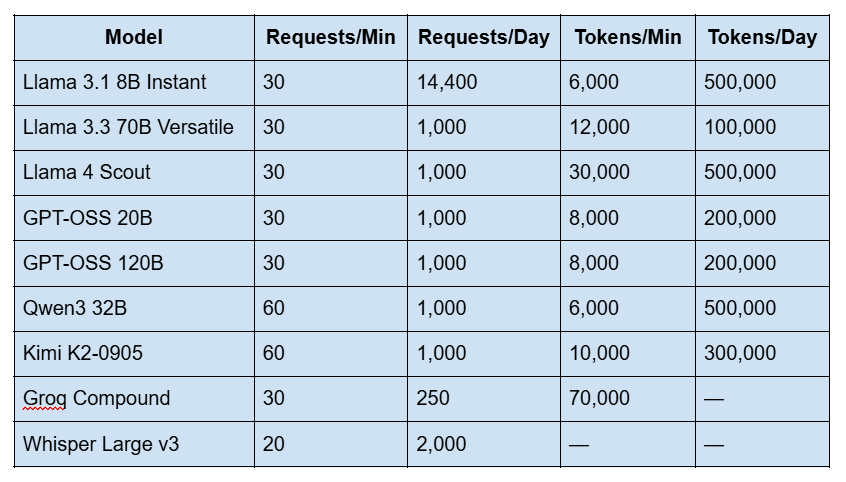
Important notes: Cached tokens do not count toward your rate limits. Limits are applied at the organization level, not per user. Check your current limits at console.groq.com/settings/limits. If you hit limits, you'll receive a 429 Too Many Requests error.
How to Access Groq API Endpoints: Step-by-Step Guide
Step 1: Get Started with Groq
Access the Groq API page at https://console.groq.com/keys and click Login. Authentication options include:
- Active email
- Gmail account
- GitHub ID
Step 2: Create Groq API Key
- Navigate to the "Create API Key" section
- Provide your key name
- Submit to register
- Copy the generated key immediately (it won't be shown again)
- Click 'Done'
The key will be visible on your profile for future reference.
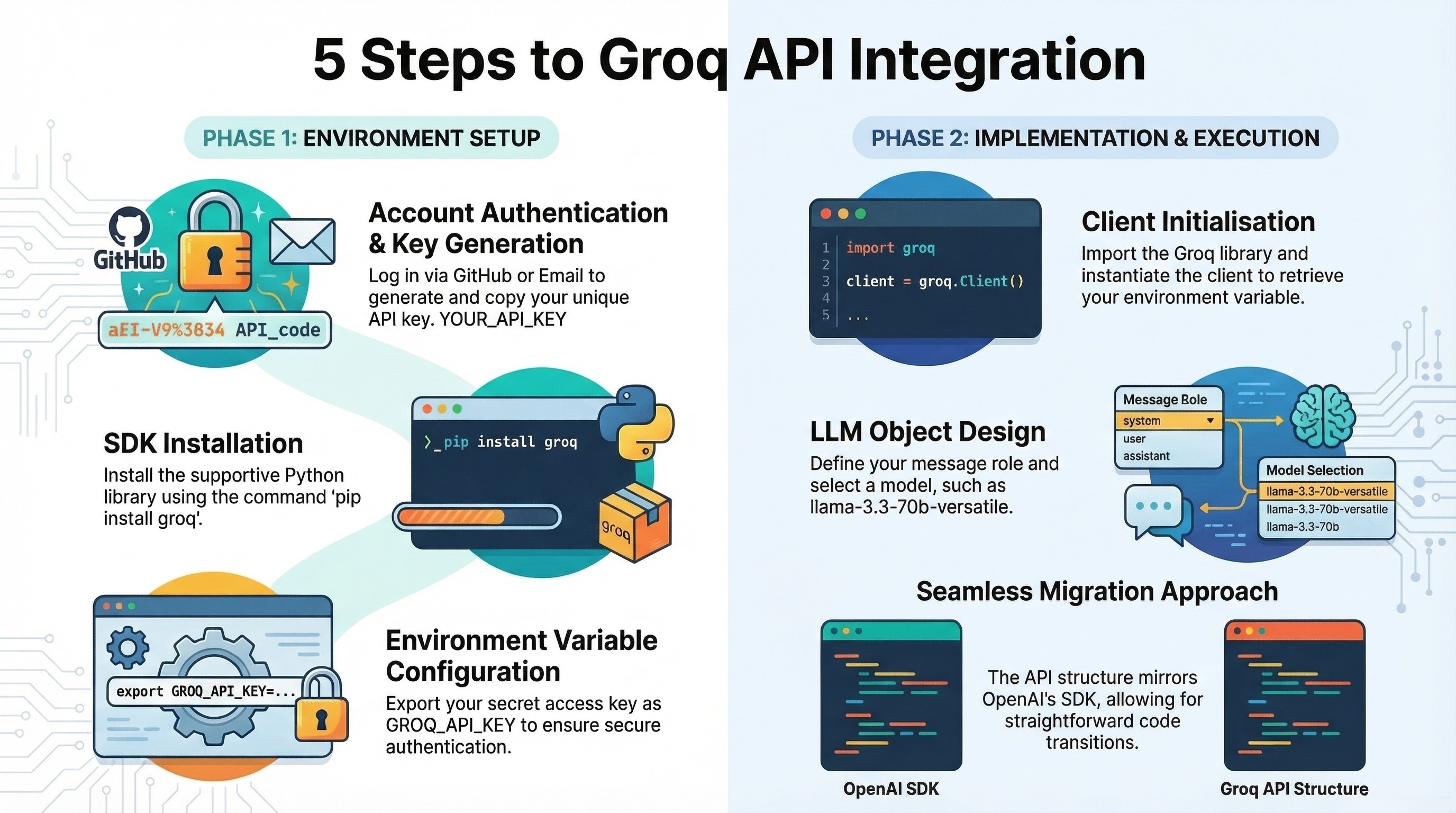
Step 3: Install Supportive Library
Install Groq's Python SDK using:
pip install groq
Set up the secret access key as an environment variable:
export GROQ_API_KEY="<your-api-key>"
Step 4: Code the API Integration
Import Libraries:
import os
from groq import Groq
Instantiate Groq Client:
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
This code activates API key retrieval from environment variables and forwards it to the api_key argument.
Step 5: Design Custom LLMs
Initialize an LLM object using:
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Explain the importance of low latency LLMs",
}
],
model="llama-3.3-70b-versatile",
)
print(chat_completion.choices[0].message.content)
The API follows an approach similar to the OpenAI SDK, so migration is straightforward if you're already using openai.ChatCompletion.create().
Using Groq API with LangChain
For LangChain integration, install the LangChain-Groq library:
pip install langchain-groq
Then create a ChatGroq object:
from langchain_groq import ChatGroq
llm = ChatGroq(
model="llama-3.3-70b-versatile",
temperature=0,
)
response = llm.invoke("What are the benefits of LPU inference?")
print(response.content)
Groq's Language Processing Unit enables quick and accurate responses while working with LangChain.
Performance Comparison: Is Groq Faster Than Other APIs?
Recent analysis from ArtificialAnalysis.ai demonstrates that Groq's inference speeds remain industry-leading. The original benchmarks showed Groq's Llama 2 Chat (70B) achieving a throughput of 241 tokens per second — nearly double the speed of competitors including OpenAI, Microsoft Azure, Fireworks, Amazon Bedrock, and Perplexity.

Evaluation Parameters:
- Throughput versus price
- Latency versus throughput
- Throughput over time
- Total response time
- Throughput variance
Groq API outperformed peers on all fronts by addressing LLM bottlenecks such as high computing density and memory bandwidth, promoting faster text sequence generation.
2026 Update: With the newer model lineup, speeds have improved substantially. GPT-OSS 20B now runs at 1,000 tokens/second, and Llama 4 Scout achieves 750 tokens/second on the Groq LPU — roughly 3x the throughput benchmarked when this guide was first published. For teams evaluating inference providers, the speed gap between Groq and cloud-hosted alternatives has widened further, particularly for latency-sensitive use cases like real-time chat and voice agents.
Using Groq in Production — What Businesses Should Know
If you've read this far, you probably already understand what the Groq API does. This section is for the person evaluating whether it makes sense as infrastructure for a real product — not a weekend prototype.
When Groq makes sense
Groq's core advantage is deterministic, ultra-low latency inference. That matters most when your users are waiting on the other end: customer-facing AI agents, real-time chat interfaces, voice bots where every 100ms of delay degrades the experience. If you're building an internal batch pipeline that processes documents overnight, latency is less important and the cost calculus changes. But if you're shipping a product where an AI agent needs to respond in under a second, Groq is currently the fastest path to get there.
The cost picture at scale
Groq's pricing is competitive at the lower end — Llama 3.1 8B at $0.05 per million input tokens is essentially free for most workloads, and even the 70B model at $0.59/M is reasonable compared to hosted GPT-4 alternatives. The Batch API (50% off) and prompt caching (another 50% off cached inputs) make high-volume production workloads significantly cheaper than they appear at list price. For teams processing millions of tokens daily, these discounts compound. Run the numbers for your specific workload before assuming Groq is more expensive — it often isn't once you factor in the speed advantage reducing infrastructure and timeout costs.
What to plan for
Model availability on Groq lags behind providers like AWS Bedrock or Azure OpenAI — you won't find every model here. But the models they do host (Llama 4, GPT-OSS, Qwen3) cover the vast majority of production use cases. The free tier is generous enough for development and testing, but you'll hit rate limits quickly in production. Plan for a paid account from day one if you're shipping to real users. Also worth noting: Groq Compound (their agentic AI system) is now in GA, which means you can get web search, code execution, and multi-step reasoning as a managed service — no need to orchestrate agents yourself.
Talk to our team
At Assistents by Ampcome, we've built production AI agents on Groq's infrastructure for clients across healthcare, finance, logistics, and retail. If your engineering team sent you this guide because they're evaluating Groq for your next project, we can help you move from proof-of-concept to production faster.
Conclusion
Achieving optimal performance with Groq API requires both understanding the technology and having the implementation expertise to deploy it at scale. Groq's LPU architecture represents a genuine shift in inference speed — and with the 2026 model lineup, pricing, and agentic capabilities, it's become a serious contender for any team building AI-powered products.
Ampcome specializes in building production AI agents and integrations using the latest inference infrastructure, including Groq. Whether you're exploring Groq API for the first time or ready to scale an existing implementation, our team can help.
FAQs
Is the Groq API free to use?
Yes. Groq offers a free tier with no credit card required. You can sign up at console.groq.com and immediately start making API calls to all supported models. The free tier has rate limits (for example, 30 requests per minute and 14,400 requests per day on Llama 3.1 8B), but there's no time limit on how long you can use it. You only need to upgrade to a paid plan when your usage exceeds the free tier limits.
What are the Groq API free tier rate limits in 2026?
Limits vary by model. The most generous free limits are on Llama 3.1 8B Instant (30 RPM, 14,400 requests/day, 500K tokens/day) and Llama 4 Scout (30 RPM, 1,000 requests/day, 500K tokens/day). Larger models like Llama 3.3 70B have tighter limits (30 RPM, 1,000 requests/day, 100K tokens/day). Groq Compound is the most restricted at 250 requests per day. See the full rate limits table above for every model. You can also check your specific limits at [console.groq.com/settings/limits](https://console.groq.com/settings/limits).
What models are available on Groq API?
As of March 2026, Groq supports: Llama 4 Scout (17Bx16E), Llama 3.3 70B, Llama 3.1 8B, OpenAI GPT-OSS 120B, OpenAI GPT-OSS 20B, Qwen3 32B, Kimi K2 (1T parameters), Groq Compound (agentic system), plus Whisper for speech-to-text and Orpheus for text-to-speech. Previously available models like Gemma 2, Mixtral, and Llama 2 have been deprecated. Groq adds new models regularly — check [console.groq.com/docs/models](https://console.groq.com/docs/models) for the live list.
How much does the Groq API cost?
Groq uses pay-as-you-go pricing per million tokens. The cheapest model is Llama 3.1 8B at $0.05/M input tokens and $0.08/M output tokens. Mid-range models like Llama 3.3 70B cost $0.59/M input and $0.79/M output. The most expensive is Kimi K2 at $1.00/M input and $3.00/M output. Groq also offers two significant discounts: the Batch API (50% off for non-real-time jobs) and Prompt Caching (50% off input tokens when prompts repeat). There are no minimum spend requirements.
Is Groq faster than OpenAI?
Yes, significantly. Groq delivers 400–1,000+ tokens per second depending on the model, compared to 50–120 tokens per second for OpenAI's GPT models. That's roughly 5–10x faster for token generation. The speed advantage comes from Groq's custom LPU (Language Processing Unit) hardware, which uses SRAM-only memory and deterministic execution to eliminate the memory bandwidth bottleneck that limits GPU-based inference. The tradeoff is that Groq only hosts open-source and open-weight models — you can't run proprietary models like GPT-4o or Claude on Groq.
How do I get a Groq API key?
Go to [console.groq.com](https://console.groq.com), sign up with your email, Gmail, or GitHub account, then navigate to API Keys in the sidebar. Click "Create API Key," name it, and copy the generated key immediately — it won't be shown again. Set it as an environment variable (`export GROQ_API_KEY="your-key"`) and install the Python SDK with `pip install groq`.
Can I use the Groq API with LangChain?
Yes. Install the `langchain-groq` package (`pip install langchain-groq`) and use the `ChatGroq` class. It works as a drop-in replacement for other LangChain chat model providers. Groq also supports the OpenAI-compatible API format, so any tool built for the OpenAI SDK can be pointed at Groq's endpoint with minimal code changes.
What is the difference between Groq and Grok?
Groq (with a Q) is an AI inference company that builds custom LPU chips for running open-source language models at high speed. Their product is an API for fast LLM inference. Grok (with a K) is xAI's conversational AI model, similar to ChatGPT. They are completely different companies and products despite the similar names.
What is Groq Compound?
Groq Compound is Groq's agentic AI system, now in general availability as of 2026. It combines fast LLM inference with built-in web search, code execution, and multi-step reasoning capabilities. Instead of building your own agent orchestration layer, you can use Groq Compound as a single API call that handles tool use, research, and reasoning automatically. It's available on both free and paid tiers (limited to 250 requests/day on free).
Is Groq SOC 2 and HIPAA compliant?
Groq has achieved SOC 2 compliance. For HIPAA compliance and enterprise security requirements, Groq offers an Enterprise plan with additional data handling guarantees. Contact Groq directly at [groq.com](https://groq.com) for details on enterprise compliance, or [talk to Ampcome](https://www.ampcome.com/contact) if you need help building HIPAA-compliant AI applications on Groq infrastructure.
What happens when I hit Groq rate limits?
You'll receive a `429 Too Many Requests` HTTP error. The response headers include `retry-after` indicating how long to wait before retrying. Best practices: implement exponential backoff in your code, use prompt caching to reduce token consumption (cached tokens don't count toward limits), and consider the Batch API for non-real-time workloads. If you consistently hit limits, upgrade to a paid tier for higher allocations.

Transform Your Business With Agentic Automation
Agentic automation is the rising star posied to overtake RPA and bring about a new wave of intelligent automation. Explore the core concepts of agentic automation, how it works, real-life examples and strategies for a successful implementation in this ebook.
Sarfraz Nawaz is the CEO and founder of Ampcome, which is at the forefront of Artificial Intelligence (AI) Development. Nawaz's passion for technology is matched by his commitment to creating solutions that drive real-world results. Under his leadership, Ampcome's team of talented engineers and developers craft innovative IT solutions that empower businesses to thrive in the ever-evolving technological landscape.Ampcome's success is a testament to Nawaz's dedication to excellence and his unwavering belief in the transformative power of technology.
More insights
Discover the latest trends, best practices, and expert opinions that can reshape your perspective


.jpg)




Contact us

